Simple to use
Create, manage and delete backends with the click of a button.
MENU



A GraphQL Backend-as-a-Service for dynamic web applications
Create, manage and delete backends with the click of a button.
Upload GraphQL schema and send GraphQL queries to your backend.
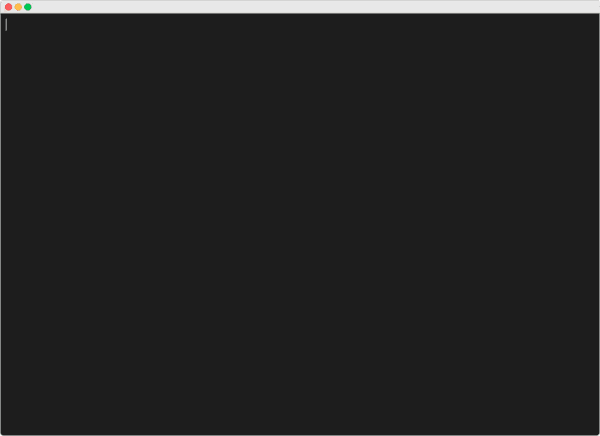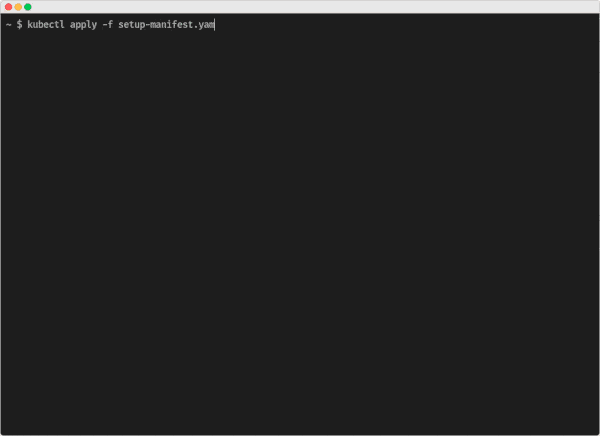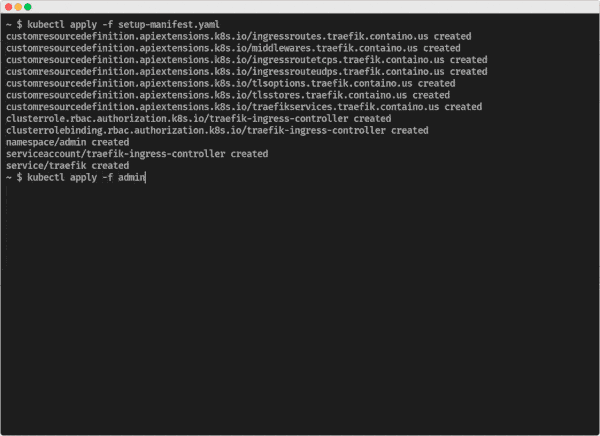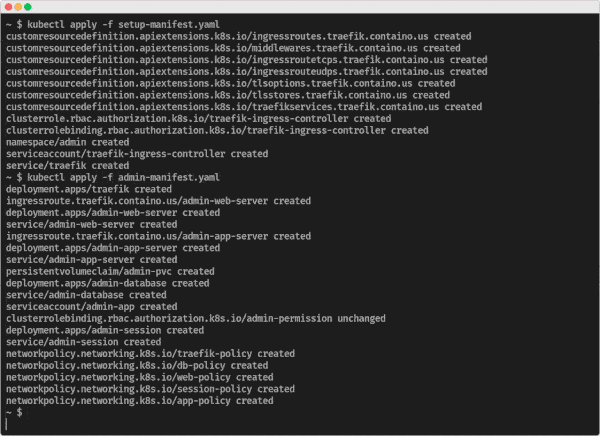
Deploy to any cloud provider using Kubernetes with just a few commands.

Satellite is an open-source GraphQL backend-as-a-service (BaaS). It lets teams easily deploy and manage GraphQL backends for web applications.
Satellite abstracts away the complexity of building a GraphQL backend. It lets the application developer define their entire backend using only a single input - a GraphQL schema. Satellite's multi-instance architecture, based on Kubernetes, lets developers create and use as many backends as they need. Satellite is a great fit for new applications where ease of use and quick deployment are priorities.
In this case study, we'll describe both why and how we designed and built Satellite. Satellite was born from our desire to make setting up a GraphQL backend easier. We overcame many technical challenges to achieve this.
To explain Satellite's design, we'll first discuss the general architecture of a modern web application.
Web applications can be thought of as having two parts - the frontend and the backend. The frontend is what the user sees when using the application. It is responsible for an application's appearance and for handling user interactions. On the other side of an application is the backend. It handles the business logic and data persistence operations needed to power the frontend.

Modern applications often separate the backend from the frontend. This split architecture allows frontend and backend teams to work independently. It also allows development of different frontend client applications which use the same backend [1]. Given the advantages of this decoupled architecture, we need to think about how the frontend and backend communicate.
An API, or Application Programming Interface, provides a well-defined way for computer systems to interact with each other. There are many different types of APIs. They all provide some way for one system to access the functionality of another system. It makes sense, then, for the frontend of a web application to communicate with the backend using an API [2]. An API that lets a frontend and backend communicate using HTTP is called a web API. In a web API, the backend server produces the API and the frontend client consumes it.

There are many different ways to build a web API. The state-of-the-art for web APIs has evolved over the years, and API designers are always finding better solutions to the challenges they are facing.
This story starts in 2011, when Facebook decided to completely re-write their iOS app. Previously, their mobile app had been a wrapper around the Facebook webpage. They determined they needed to create a new, native app to provide the kind of experience they wanted for their mobile users. Their design required the frontend to be separated from the backend, and for the two sides to communicate with an API. This was the first time Facebook had tried to develop an app like this. They soon had issues when trying to reuse the existing API for the News Feed feature [3].
For Facebook’s News Feed, it wasn’t as simple as retrieving a story and all the information for that story. Each story is interconnected, nested, and recursive. The existing APIs weren’t designed to allow developers to deliver a news feed-like experience on mobile. They didn’t have a hierarchical nature or let developers select the exact data they needed. They were, in fact, designed to return HTML back to a web browser.

This meant that the client application would need to make several round-trips to the API to get the information it wanted. For example, it might have to first get one story, and from it determine what other stories it needed to request to complete the feed. Then it might keep repeating that process over and over until it got all the information it needed. Additionally, each response would contain a lot of data that wasn’t needed. These factors combined resulted in slow network performance for the new app.
At this point, it was clear to Facebook that they needed to design a better API for their News Feed to improve the mobile experience. A quote from Nick Schrock, one of the co-creators of this new API which is now called GraphQL, highlights their focus on frontend development:
"We tried to design what we thought was the ideal API for frontend developers, and then work backwards to the technology."
- Nick Schrock, GraphQL co-creator
A key feature of GraphQL let it power the mobile apps Facebook had envisioned: letting the frontend client request exactly the data it needs. This eliminates the issue of over-fetching and the need for multiple round trips. This is critical for mobile applications which have limited bandwidth and need fast response times.

One other important aspect of a GraphQL API is that it uses a strongly typed system to describe its capabilities. This allows clients to use a process called introspection to see exactly what they are able to do with the API, making GraphQL effectively self-documenting [4]. This has also lead to the development of many client-side tools.
Because of its unique features, GraphQL caught on quickly at Facebook, and ended up being used heavily in their mobile application. It was an internal tool from 2012 until 2015; that year, they released an open-source version. Soon after GraphQL was open-sourced, many other companies began using it, including AirBnB, Twitter, Netflix, and Github. It has continued to grow in adoption ever since [5].
Now that we understand the types of problems that GraphQL was created to solve, we can take a closer look at what GraphQL is and how it works.
GraphQL is a query language for APIs. In this section, we'll explain in more depth how it works and what is involved in building a GraphQL application.
GraphQL is actually a specification that describes its type system and query language [6]. Both of these will be covered in more detail later. For now, keep in mind that this specification can be implemented in any programming language. It's not specific to one application or architecture. There are server-side implementations of the GraphQL specification in many programming languages. These server-side implementations are called GraphQL servers.
GraphQL servers communicate with clients using HTTP. The GraphQL server parses the request into an abstract syntax tree (AST) then walks the tree and determines how to respond to the request. Once the GraphQL server has assembled the request, the request is returned to the client as a JSON object over HTTP.
With the GraphQL specification implemented on the server, the frontend can query it. Since the data is defined according to GraphQL's type system, the frontend structures its queries according to those types. The frontend can then specify exactly the data it wants in a query to the GraphQL server. The server will return that data in a JSON object.

Enabling this kind of interaction for frontend clients worked great for Facebook's News Feed API.
You should now have an idea of what kind of problems GraphQL was created to solve and a general understanding of how it works. You might even be interested in creating your next application using a GraphQL API. There are several factors to consider if you do, though.
First, we'll cover the overall architecture required for a web application backend.
As a first step in understanding what it takes to build a GraphQL backend, let's take a look at the general setup for a backend:

A backend is usually built with a 3-tier architecture [7]. The different "tiers" in this architecture serve the following purposes:
This kind of architecture is the foundation for building any feature our application might need.
Given the basic architecture of a backend, we can start to imagine all the different things that a backend might need to do. These might include enabling SSL connections, managing realtime connections, providing hosting for frontend assets, and more. These all need to be set up and configured.

Any one of these tasks is a topic unto itself. For the backend of a GraphQL application, though, producing the GraphQL API is a subject we'll need to explore further.
Individual developers and companies have mentioned the challenges associated with implementing GraphQL in production applications.
Arnaud Lauret, author of the book "The Design of Web APIs", mentions the new challenges that a GraphQL API brings [8]:
“GraphQL does not ease an API provider’s job and brings new challenges.”
- Arnaud Lauret, author of The Design of Web APIs
In an article from PayPal's engineering blog, a similar challenge is mentioned - GraphQL is different than what developers may be used to [9]:
“Ensure that architects and API designers are on board with GraphQL ... More than likely, they have designed REST APIs for years. GraphQL is different.”
- Scaling GraphQL at Paypal - Paypal Engineering Blog
With this in mind, we are ready to proceed with discussing how one produces a GraphQL API.
To produce a GraphQL API, we need to run a GraphQL server. As mentioned earlier, a GraphQL server is software that receives and responds to GraphQL requests. The behavior of a GraphQL server is defined using two inputs: a GraphQL schema and resolver functions. A GraphQL schema defines “what” the GraphQL server can do using the GraphQL type system, and resolver functions tell it “how” to do it [10].
A diagram of a GraphQL server is shown here. A GraphQL schema defines the GraphQL API. Then the API invokes the necessary resolver functions. Finally, the resolvers carry out the actions needed to produce a response, like querying a database:

GraphQL schema declaratively defines the functionality of a GraphQL API [11]. Schema is made up of types, and types have one or more fields.
A basic GraphQL schema is shown here. It has several types - the “Person” type is an object type. Object types make up the “things” of your API. Each type will also have fields. For the Person here, there is a name and phone field, which are a string and integer. You can think of fields like the properties of your objects.

There are many more types than just objects. Two important ones are query and mutation types. These describe what actions you can do with your object types. Queries define how to retrieve data and mutations define how to create or change data. Here we have a query to find a person by name, and a mutation to create a new person.
Keep in mind that these definitions of queries and mutations don’t say anything about how the API gets the job done. They only describe what the API can do!
Resolvers are functions that tell the GraphQL server how to respond to requests.
Unlike the schema, which has to follow the requirements of the GraphQL specification, resolvers are flexible. They are just functions, and you can do anything with them that you would do with any other function. The only requirement is that the function needs to return a value(s) which correspond to the field(s) specified by the schema [12].
In this example, the resolvers correspond to the respective query and mutation types that were defined in the GraphQL schema.

With the GraphQL schema and resolver functions defined, we have everything we need to initialize the GraphQL server and produce a GraphQL API.
We now see the big picture of what goes into creating a GraphQL backend. Besides the architecture and configuration needed for a typical backend, there are also the inputs needed to define the GraphQL API: schema and resolver functions.

For a frontend developer wanting to get a GraphQL application up and running quickly, that’s a lot to think about. Because of this, we wanted to find a quick and easy way to setup a simple GraphQL backend.
Ideally, the developer wouldn’t have to think about the backend design at all. The standard backend components and configuration should be set up automatically, as should the lower-level GraphQL configuration, like resolver functions.
In order to solve the aforementioned problems, we decided to build a backend-as-a-service (BaaS). A BaaS provides an abstraction over all the functionality and complexity of the backend.
A BaaS encapsulates the underlying architecture that a backend needs - the web server, app server, and database. It also provides pre-configured features like SSL certificates and static frontend hosting. The functionality of the backend is made available to frontend applications through an API [13].

With a BaaS, you simply ask for a backend to be created. Then it gives you an endpoint to access that backend's functionality.
As we've seen, a BaaS facilitates frontend development. It abstracts away the complexity of the backend, allowing for faster application development.
This abstraction does come with costs, though. For example, the BaaS itself still requires setup and maintenance. Also, with these kinds of services, you gain abstraction and sacrifice control. The table below shows how a BaaS compares to two other services which provide abstraction over backend concerns: infrastructure-as-a-service (IaaS) and platform-as-a-service (PaaS).
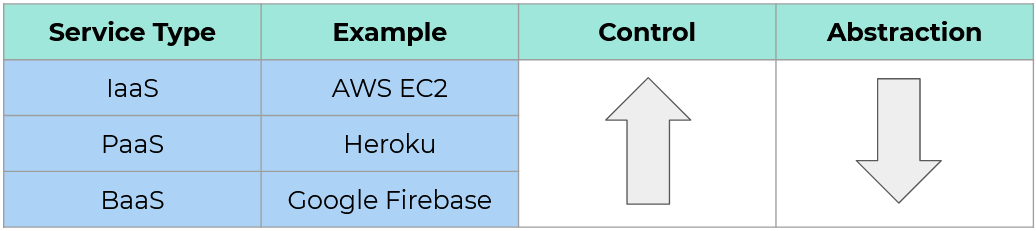
An IaaS provides the lowest level of abstraction. The developer configures everything from the operating system on up. That makes it low in abstraction but high in control.
A PaaS provides more abstraction than an IaaS, but less than a BaaS. The developer provides all the application code for the backend. The platform handles the operating system configuration and deployment.
At the highest level of abstraction is a BaaS. The developer no longer needs to provide any backend code or handle any backend configuration, but they can't control how the service works internally.
Giving up control over the internals of the backend seemed like a reasonable trade-off for an application that requires rapid development.
There are several existing GraphQL BaaS options to choose from. These can be grouped into two categories: managed services and open-source solutions.
Managed services are paid, proprietary services and are fully supported by a provider. Using a paid service takes care of all the details of setting up and managing backends. In general, they are easy to use - with some caveats. AWS Amplify, for example, has a close integration with other AWS services. That makes it a great option if you are committed to using AWS services for your entire application. It's possible, but more difficult, to use it with non-AWS services. Since there is no need to deploy anything to use these managed services, they're very simple to use.
These managed services also tend to have many features. Services like 8Base and Nhost provide just about any feature you could want from a backend even beyond the GraphQL API. Slash GraphQL has comparatively fewer features. It does, though, have some advanced options like the ability to run custom logic via serverless lambda functions.
For open-source options, the most popular is probably Parse Platform. Parse is a self-hosted platform that provides a backend with all the features you could need for your application, including a GraphQL API. Unlike the managed services, you can host Parse anywhere you want. It gives you full control over your data and infrastructure.
Another, less well-known GraphQL BaaS is Spacecloud. It offers a similar wide range of features as Parse and also lets you self-host it wherever you want.
While the existing GraphQL BaaS options have many useful features, they have their tradeoffs as well.
Although managed services need minimal effort to deploy and are generally easy to use, they are not open-source. With these services, you don’t have any control over how your application and its data are hosted. You also run the risk of vendor lock-in if your application outgrows the BaaS.
With the existing open source options, you maintain control of your data but have more complicated deployment and usage. You will need to worry about things like selecting and configuring a database with both Parse and Spacecloud, for example. With their wide range of features and options, it can take some time to learn how to use them once they are deployed.
After reviewing the existing BaaS options, we saw that there was an opportunity for a self-hosted GraphQL BaaS that is easy to deploy and use. Two main things influenced our idea. One is the simplicity of managed services. The other is the ability to self-host an open-source solution and maintain full control of an application and its data.
The table below shows where Satellite fits compared to some existing options:
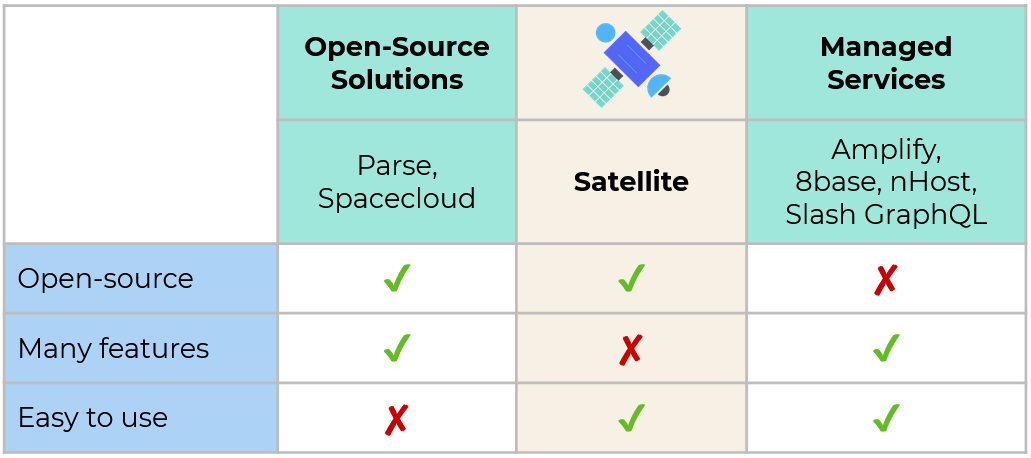
Compared to the other GraphQL BaaS options, Satellite has fewer features. We kept it that way to simplify deployment and ensure that it was intuitive to use. Like other existing open-source options, you can host Satellite anywhere you’d like.
Since Satellite doesn’t have a huge number of features, it won't be a good fit for every application. But if you want an open-source solution to quickly get a GraphQL backend running with minimal features, Satellite might be a good option.
The Satellite core application represents a single backend instance. It provides a GraphQL API for client applications to access, a persistent data store, and static file serving for frontend hosting.

These features are made possible using several components under the hood. First is an Nginx web server, used for serving static files and routing incoming requests. Next is a NodeJS Express application server, which allows administrative actions to be made on the Satellite instance. Finally, a Dgraph graph database is used to store persistent data.
Our priority while designing Satellite was to keep it easy to use. In this rest of this section, we'll explain the main problems we solved in achieving that goal and how we arrived at our current architecture.
When we started building Satellite, we faced a question: how do we build a GraphQL backend that works for any application without knowing what kind of data that application will need ahead of time? We needed to build a “generic” GraphQL backend that would work for any application.
To answer that question, we had to determine the best way to allow a developer to define the structure of their application's data.
The backend for a GraphQL application will normally need to deal with interconnected, related data. One way to handle this is to use a relational database with a GraphQL layer over it. The GraphQL queries from the client would get translated to SQL queries by resolver functions. This solution has the drawback of needing two sets of schema - one for the relational database and one for the GraphQL API.
Requiring a database schema in addition to the GraphQL schema would add another piece of configuration that must be provided to the backend. That was something we wanted to avoid to keep Satellite simple.
At first, we thought we could come up with a way to generate a relational database schema from a GraphQL schema. This would eliminate the need for two schemas and make it possible to define the structure of the backend's data using only a GraphQL schema.
But what would this look like? Would it even be possible?
For a simple GraphQL schema, consisting of only a single object type like the one shown below, this idea could work. We could generate a database schema defining a table with columns corresponding to the object.
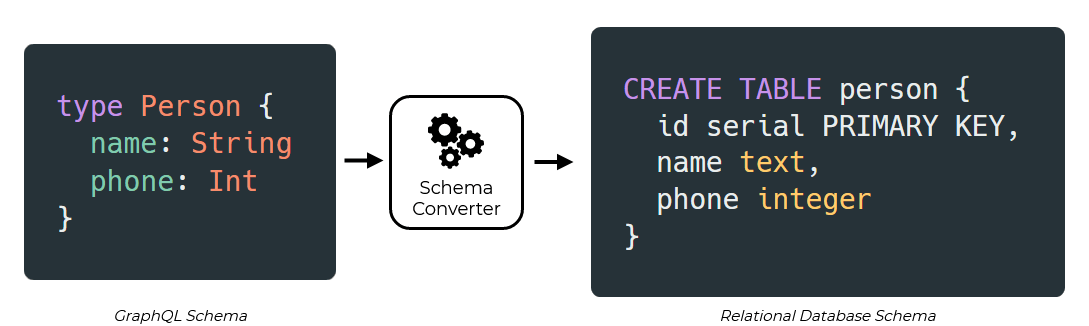
The logic for this hypothetical conversion process should've been a simple matter of converting strings. For now, we were ready to proceed to the next step.
Now that we had a way to define the data of an application, we needed a way to access the data.
As we’ve mentioned, making the data available for a GraphQL backend requires a GraphQL server to serve the API. The GraphQL server also needs to contain resolver functions for responding to requests. The challenge is that writing these resolver functions requires the developer to go "under the hood" and edit the backend’s code. To keep Satellite easy to use and preserve the encapsulation of the BaaS, this was a problem we wanted to avoid.
As a possible solution, we thought we could take a similar approach as we had for converting the GraphQL schema to a database schema, and apply it to automatically generating resolver functions. These would be functions for common actions on an application’s data - creating, reading, updating, and deleting [14]. The GraphQL server would then be initialized with those functions.
Would it be possible to do this? We again considered our very simple GraphQL schema to consider what this resolver function generator might look like:
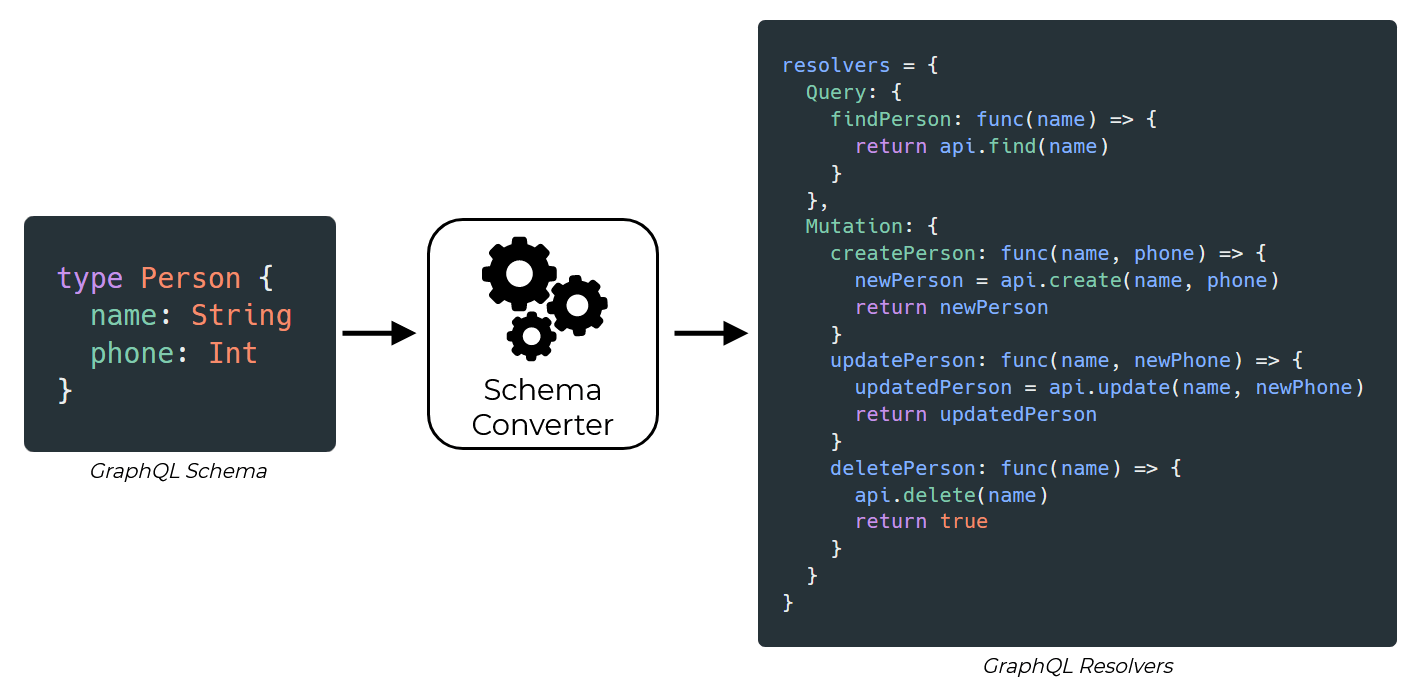
We would need four resolvers for each object type in the schema: a Query type for reading the data and three Mutation types for creating, updating, and deleting. This was getting complicated but still seemed doable. Since all the resolvers followed a similar pattern, we should've been able to generate the correct function signatures and required database actions to make it work... at least for a simple schema like this.
Our imagined schema converter would no longer only be a matter of converting strings. Now it would need to generate functions, too. But, we still felt confident enough to proceed down this path.
We could now envision a hypothetical architecture for our GraphQL backend. It would need only a GraphQL schema as an input.

The schema converter would get the GraphQL schema. Then it would generate a database schema and create the database. Next, it would generate the resolvers functions. Finally, the GraphQL server would produce a GraphQL API. It could then receive and respond to GraphQL requests from frontend applications.
But like so many things in software engineering, it turned out to be more complicated than we had assumed.
So far, we've only looked at a very simple schema - probably too simple to make an interesting application.
Difficulties arose with more complicated schema. Creating the database schema and resolver functions became much harder. The schema in the next figure shows some more complex behaviors that can be defined using the GraphQL type system:
Person has the fields name,
address, and friends:
name has the scalar type of
String. Scalar types are what we have been looking
at so far. These types repesent a peice of concrete data.
address has the type of Address. The
type Address is also defined in the schema. This is
a user defined type.
friends refers to a list of user defined
types - a list of Person types.
Address is similar to what we've seen so far,
with all of its fields being scalar types.
A schema like this allows the GraphQL API to handle relationships. That's a key feature of GraphQL, so it wasn't something we could ignore. But what would our imagined schema converter look like now?
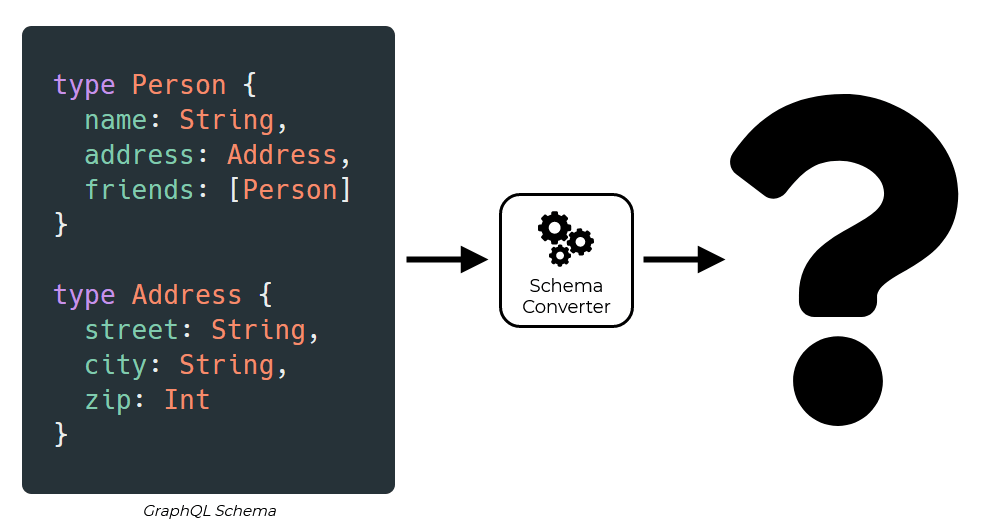
The schema converter would need to define multiple tables, foreign keys, and constraints. Besides this, we'd also have to think much harder about resolver generation.
So far, we'd been taking advantage of something called the default resolver. According to the GraphQL specification, every field in a GraphQL schema needs a resolver. If no resolver function is defined for a field, most GraphQL implementations will fall back to the default resolver [15]. The default resolver simply returns a property from the returned object with the relevant field name. For example, if we defined resolvers for every field of the simple schema we considered earlier, the resulting functions would look like this:
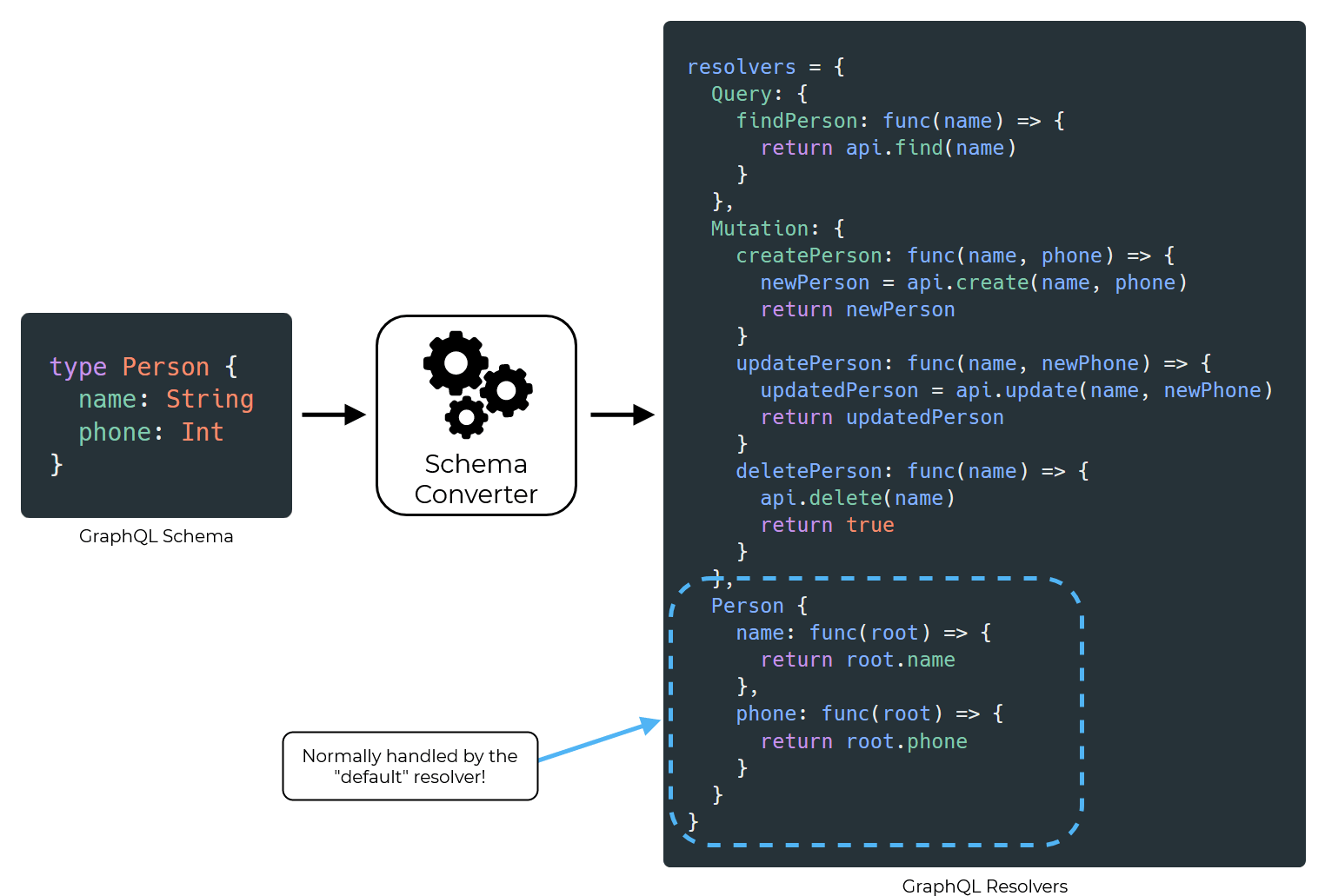
See the extra resolvers defined for Person? These are usually handled behind the scenes by the default resolver.
Clearly, with schema having fields that aren't simple scalar types, we could no longer rely on the default resolver. Our schema converter would need to be smart enough to traverse each type recursively, identify non-scalar fields and generate resolver functions for those fields. An algorithm like this would actually be similar in concept to how a GraphQL server converts an incoming request into an AST.
Although we were still confident we could pull this off, going this route looked like it would mean reinventing the wheel. We thought it would be a good time to take a step back and consider alternatives.
Our search for a simpler way to generate resolver functions from a GraphQL schema led us to consider other kinds of databases. Graph databases showed promise.
Graph databases are specialized to handle highly interconnected data [16]. They do this by treating their data as a graph - which is similar to how GraphQL treats its data. In fact, some Graph databases even have integrations with GraphQL to generate resolvers, which was exactly what we were looking for.
Two graph databases with GraphQL integrations are neo4j and Dgraph. Neo4j is the most widely used graph database [17]. Its GraphQL integration involves using an add-on to the database, which was a more complicated setup than we were hoping for.
Dgraph is less well-known that neo4j, but it has native GraphQL integration. You don’t have to install any other addons - you get the GraphQL API directly from the database.
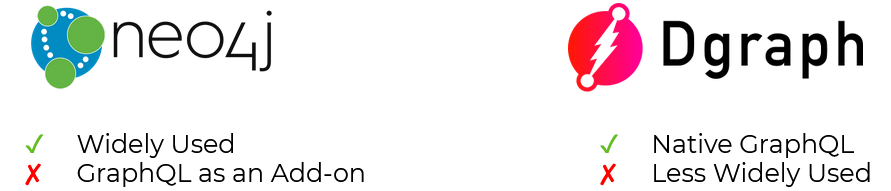
Because of its native GraphQL support, we chose Dgraph for Satellite's database. This greatly simplified our architecture.
Letting Dgraph handle resolver generation and serve the GraphQL API let us simplify our hypothetical architecture:

With Dgraph accepting a GraphQL schema as an input, we were able to remove two major components from our architecture. We no longer needed a schema converter for generating database schema and resolvers. We also didn't need a separate application server to serve the API.
At this point, the majority of the heavy lifting was done. We still had a few more problems to solve before we could get to the final Satellite backend architecture, though.
Besides a GraphQL endpoint, Dgraph exposes administrative endpoints for interacting with its GraphQL schema. They can be used for updating the schema and viewing the currently loaded schema. The frontend Satellite user would need to access these admin endpoints but they shouldn’t be accessible from the public internet. As it was, we had no way of making only the GraphQL endpoint public to the internet, while keeping the admin endpoint private.

Also, we had no way to upload or serve static files for web applications. We needed a way to resolve both of these issues before we could declare victory.
To protect Dgraph's administrative endpoints and deal with static files, we needed a couple more components.
The first component we needed was a web server to serve static files and act as a reverse proxy to the GraphQL API endpoint that Dgraph provides. We chose Nginx for this since it's an efficient and battle-tested product [18].

The second thing we needed was an application to provide a way for the developer to upload their static files and send administrative actions to Dgraph’s admin endpoint. We accomplished this by building an Express application running on NodeJS to provide a private API. The front-end developer can access the API to upload their static files and work with the GraphQL schema loaded into Dgraph.
That brought us to the final architecture for the Satellite core application, which is shown below:

The Nginx web server acts as a web-facing entry point to the backend. It can reverse-proxy GraphQL requests to Dgraph or serve static files. The NodeJS application provides a private endpoint for the developer and allows uploading static files or updating their GraphQL schema.
Satellite's core architecture makes it easy to use, but what about deployment? On one hand, we knew that we couldn't match the simplicity of deployment of a managed service. On the other, we needed to make it as easy as possible to deploy for Satellite to be a viable alternative.
At the time, to get a Satellite instance running, you would have had to manually download and configure each component. The specifics could change depending on the machine's operating system. This would be a very time-consuming and difficult process. Packaging the components of a Satellite backend, plus their dependencies, in a way that was easy to deploy was the new challenge.
After some investigation, we found a good answer to this: containers.
Containers provide a way to package an application with its dependencies in an isolated and consistent way [19]. This means that if you start a NodeJS container, that container has all the requirements to run NodeJS packaged with it. You no longer have to worry about manually installing it and setting everything up. Containers also provide isolation, meaning that whatever is going on in the container doesn’t interfere with the host system.

Another good thing about containers is that they are lighter weight than some other options like virtual machines [20]. Virtual machines need to run a guest operating system. Containers, though, create an isolated environment within the host operating system. Since Docker is the most popular way to package applications using containers, we chose it to package the components of Satellite.
Packaging Satellite using Docker containers greatly simplified the deployment of the individual components. But since a Satellite backend consists of several components, it still required manually starting and stopping each container.
Our goal was to make it possible to start the application with only a single command. Fortunately, Docker provides a tool called Docker Compose. It's designed for defining and running applications consisting of multiple Docker containers. Compose uses a YAML file to describe and configure the containers you want to run. Then it launches the containers to start the application.
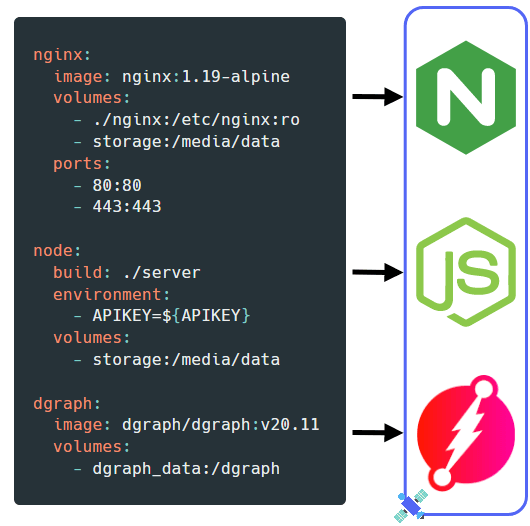
Our Docker Compose configuration for launching a containerized backend looked something like this. As you can see, the compose file can also specify various other options needed for Satellite to run. It can include things like environment variables and storage volumes used by the containers to store their data.
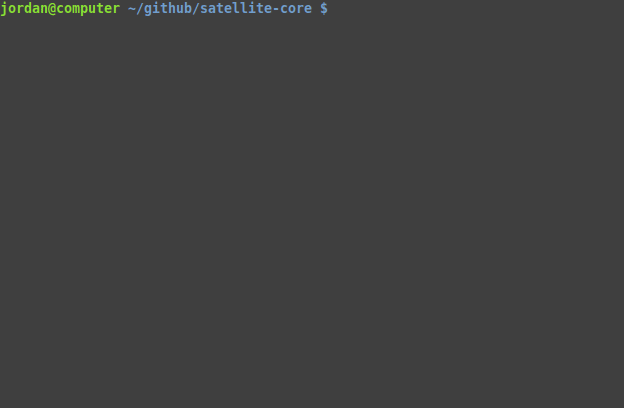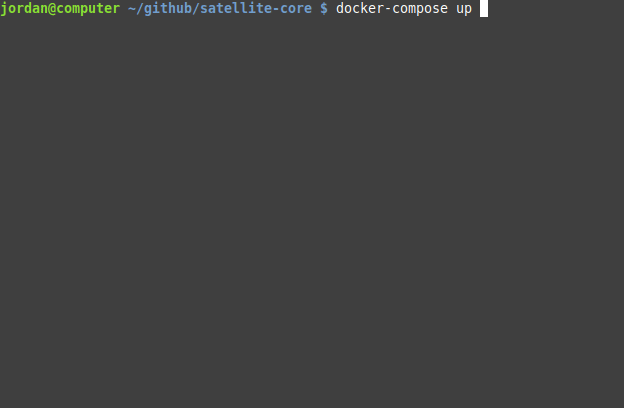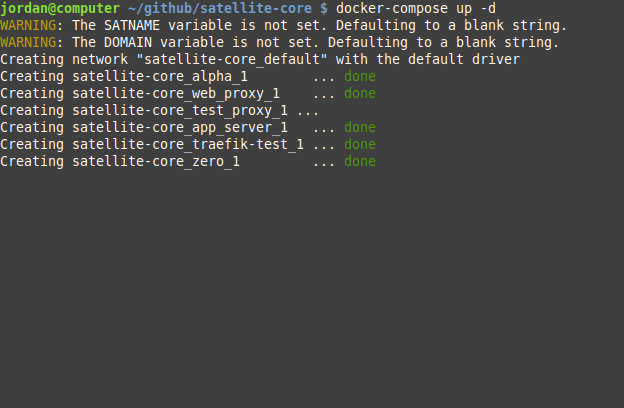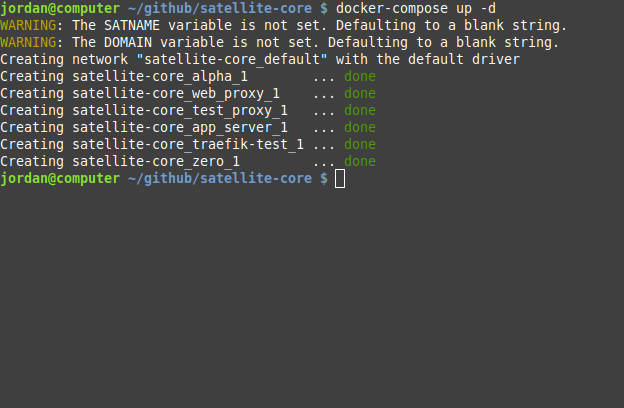
At this point, we had a system that was easy to deploy and supported one Satellite instance. This would work fine for developers who needed a single backend. What about developers who wanted to run several backends at once? For example, it's often useful for an application to have multiple versions of its backend. This could be for supporting different versions of the app for staging and production [21]. It's also possible that developers want to host more than one application at a time.
The question then became: how can we support deployment of multiple Satellite backends as a part of single framework deployment?

In a multi-instance architecture, each Satellite backend runs as a self-contained stack of containers, and those containers are not shared between applications. This type of archtecture would maximize isolation between applications while separating routing and administration logic from the core Satellite API into dedicated components. The backend for each application would be a self-contained environment comprised of the Nginx, Dgraph database, Express API, just like the single-instance deployment.
In the single-instance version of Satellite, all three components existed on one server. They could be started up as a unit using Docker Compose. Docker's bridge network connected the Dgraph, Express, and Nginx containers to each other. The Nginx server in each container exposed ports that were accessible from the public internet.

At a high level, it seemed like creating a multi-instance architecture could be just a matter of starting up multiple Docker Compose files. That architecture would look like this:

As it turns out, implementing a multi-instance architecture introduces a set of new challenges:
To accommodate increasing loads on the system, we could scale Satellite vertically or horizontally. Vertical scaling refers to adding more resources and capacity to a single server. The drawback of this approach is that the cost of scaling further rises exponentially as more capacity is added. There is also a practical limit on how much processing power a single server can have [22].
Horizontal scaling was a better solution for Satellite. It involves pooling resources of multiple servers together, and scale the number of machines according to demand. Applications are then spread across multiple servers. This approach is more cost efficient and allows virtually unlimited scalability. But, it complicates communication and routing since backends can now live on different host machines. Having several backends spread across multiple host machines could look like this:

At this point, we had a strategy for scaling Satellite to accommodate any number of individual backends. We still had several challenges to overcome in completing the multi-instance design, including:
Horizontal scaling introduces set of issues that did not exist in the single-server setup. As additional servers are added or failed servers are removed, we needed to answer the following questions:
Therefore, to spin up and tear down containerized Satellite backends on demand, we needed a tool to manage them.
For this, we used a container orchestrator. A container orchestrator is a tool to manage, scale, and maintain containerized applications. Kubernetes is Satellite's container orchestrator of choice, as it is the industry standard and all major cloud providers support it as a managed service.
To understand how Kubernetes solves the problems mentioned above, we first need to understand the concept of cluster. A cluster is a group of nodes that operate as a part of the same horizontally scaled environment. The cluster is a group of connected nodes. The nodes are machines, virtual or physical, and a node can either be a master or worker. It is the worker nodes that are responsible actually running containers, while master nodes together make up what is called a control plane, and are responsible for managing the state of the cluster and assigning containers to worker nodes.
When an application is deployed using Kubernetes, it takes the strain of distributing them across available worker nodes in the cluster, monitoring health of containers and nodes within the cluster, and restarting failed containers. In other words, it abstracts away the challenges involved in scaling horizontally and exposes a single endpoint for declaratively managing our distributed backend applications.
With Kubernetes, the components of any one Satellite backend might live on the same node or be spread across multiple nodes:
Earlier, we described how Docker Compose uses a YAML file to define and configure an application composed of containers. We showed how to use it to define a single Satellite instance.
Kubernetes works in an analogous way. It lets developers define one or more containerized applications in a manifest file. A manifest file can be written in YAML or JSON. The manifest file describes the list of components to be deployed, together with their specifications and configurations, which Kubernetes treats as the desired state of the application. Kubernetes is then responsible for starting appropriate containers and distributing them across available nodes, constantly monitoring the current state of the application and ensuring that it matches the desired state.
Kubernetes also provides a CLI for managing deployments of containerized applications. Passing the manifest file as an argument to the Kubernetes CLI allows us to spin up and tear down Satellite backends:
Having distributed individual components of our backends across multiple nodes, how can we ensure that they can communicate with one another? After all, Nginx server and the Dgraph database that belong to the same backend can end up on two different machines.
To explain how we managed component communication within Satellite backends, first we need to describe how Kubernetes handles containers.
Kubernetes wraps containers into pods. A pod is a Kubernetes object that runs a group of one or more containers. You can imagine a pod as a wrapper around one or more Docker containers. It allows Kubernetes to manage the lifecycle of the containers running inside the pod. In a single Satellite backend, each container (Nginx, Dgraph, and Express API) runs as separate pods:

Kubernetes provides a VPC (Virtual Private Network) that spans all pods running in the cluster. Each pod gets its own IP address on that network that lets it communicate with other pods in the cluster:

If a pod crashes or its specification is updated, Kubernetes will make sure that a new pod is deployed to take its place. This new pod will very likely have a different IP address, though. This means that we could not hard-code the IP addresses of separate components, because they are both ephemeral and are not known before the pod is actually deployed:

The solution is to use Kubernetes' built-in services. They provide a fixed gateway to one or more pods that comporise a specific component of an application. The one that serves our purpose in particular is ClusterIP, which is responsible for internal traffic within cluster. A pod can reach another pod using the latter's service name, instead of its IP address. The name of the service is then resolved by internal DNS to service's IP address. The service, in turn, proxies requests to a set of pods according to its specification in the manifest file.
To ensure reliable component communication in a Satellite backend, we used Kubernetes services. The diagram below shows how this works. Here, the pod running the Express API is defined as part of the app-server service. Requests from the Nginx pod can be proxied to the Express API pod through the app-server service. The domain name in the request would be the name of the service, app-server.

We now had a way for components to communicate with other components within the Kubernetes cluster. But we still had a critical networking challenge: how do we route requests from the internet to the correct Satellite backend?
Kubernetes provides another type of service, called LoadBalancer service. When included in manifest, it automatically gets the managed Kubernetes service provider to provision an external load balancer for the cluster. The load balancer provides an internet-accessible IP address. It forwards incoming requests to the correct ports on cluster nodes. The service running on the node then ensures that request gets to the appropriate pod.

The problem with this approach is that each backend instance's Nginx pod would need its own LoadBalancer service. Beyond single backend this method grows unwieldy. The reason for this is that each LoadBalancer service needs its own dedicated external load balancer. Having an external load balancer for each Satellite instance is prohibitively costly and hard to manage. Also, services' ports cannot conflict with one another, which means all backend instances but one would have to resort to using ports other than standard 80 and 443.

At this point, our ideal setup was to have one external load balancer to forward external requests to a single load balancer service. The single load balancer service would be configured to send requests to the correct backends.
To do this, we used Traefik. Traefik is a reverse proxy that can forward requests based on a set of user-defined routing rules. We deployed Traefik as a pod within the cluster. This let Traefik use the ClusterIP services to forward requests to the correct pods.
In a Satellite deployment, the external load balancer receives requests and forwards them to the single load balancer service. The load balancer service then forwards requests to Traefik. Traefik routes requests to the correct Satellite backend and pod using the request's subdomain, domain, and path.

In this setup, the hostname of each Satellite backend is dynamically generated based on the backend's name. Having to request SSL certificates manually would be cumbersome and tricky. We could run a script every time a backend instance is deployed to automatically request SSL certificates. Luckily, we did not have to. A benefit of using Traefik is that it can be configured to request SSL certificates for subdomains automatically. This lets Satellite use HTTPS by default for every new backend.
At this point, we had all the functionality for the multi-instance architecture built. The final step was to provide some easy way for a developer to interact with it.
Our multi-instance came with the cost of extra application layers for container orchestration and networking.
To keep these layers simple to interact with, we needed one more thing: an intuitive GUI. That would let a developer spin up, tear down, or manage their Satellite backends.
The first step in building an admin panel was allowing users of a Satellite deployment to register and authenticate at 'admin.domain.com'. Once authenticated, a frontend developer would be authorized to manage their backend. Upon sign in, frontend developers are presented with a UI that allows them to spin up a new backend by specifying a name. They can also tear down a backend from the admin panel with the click of a button.
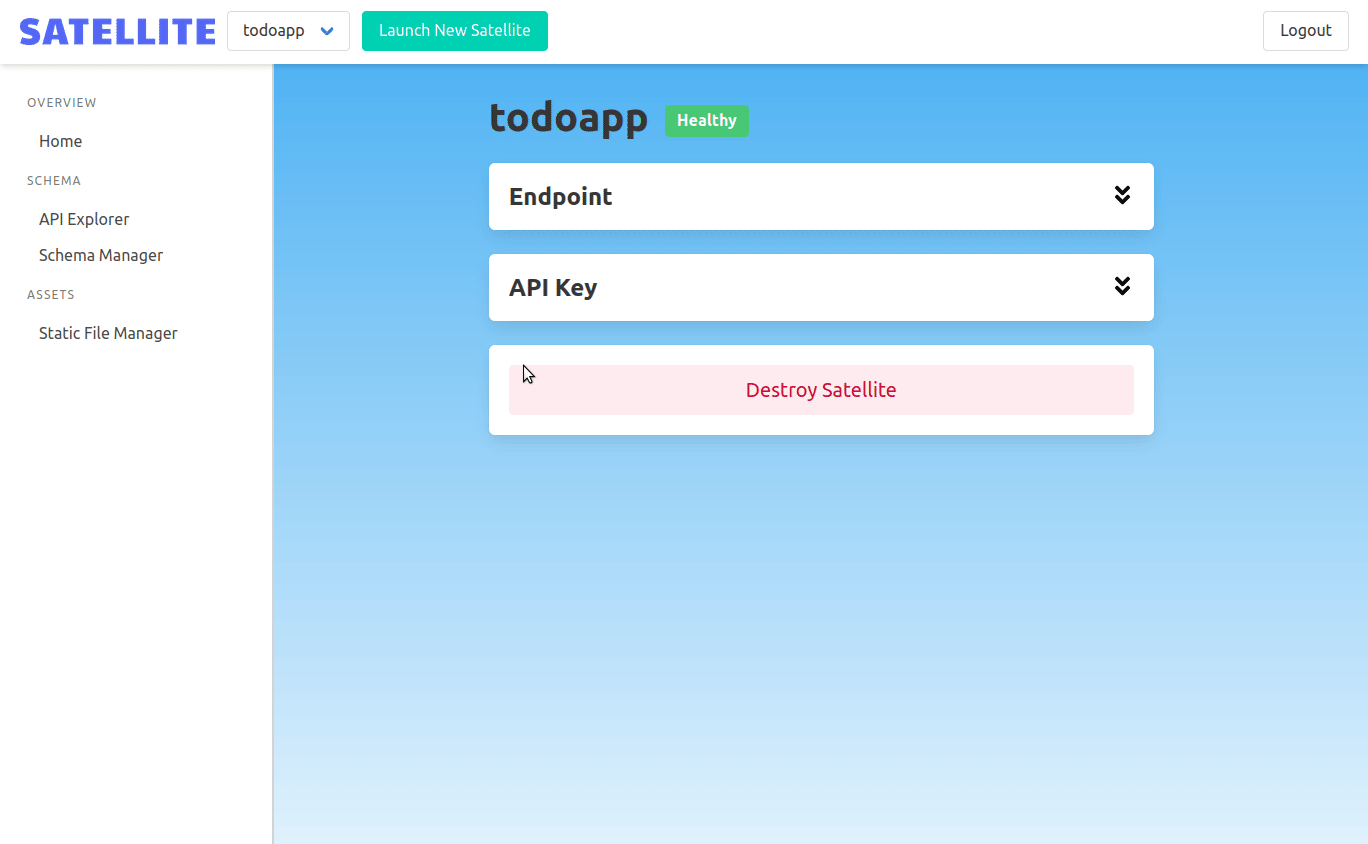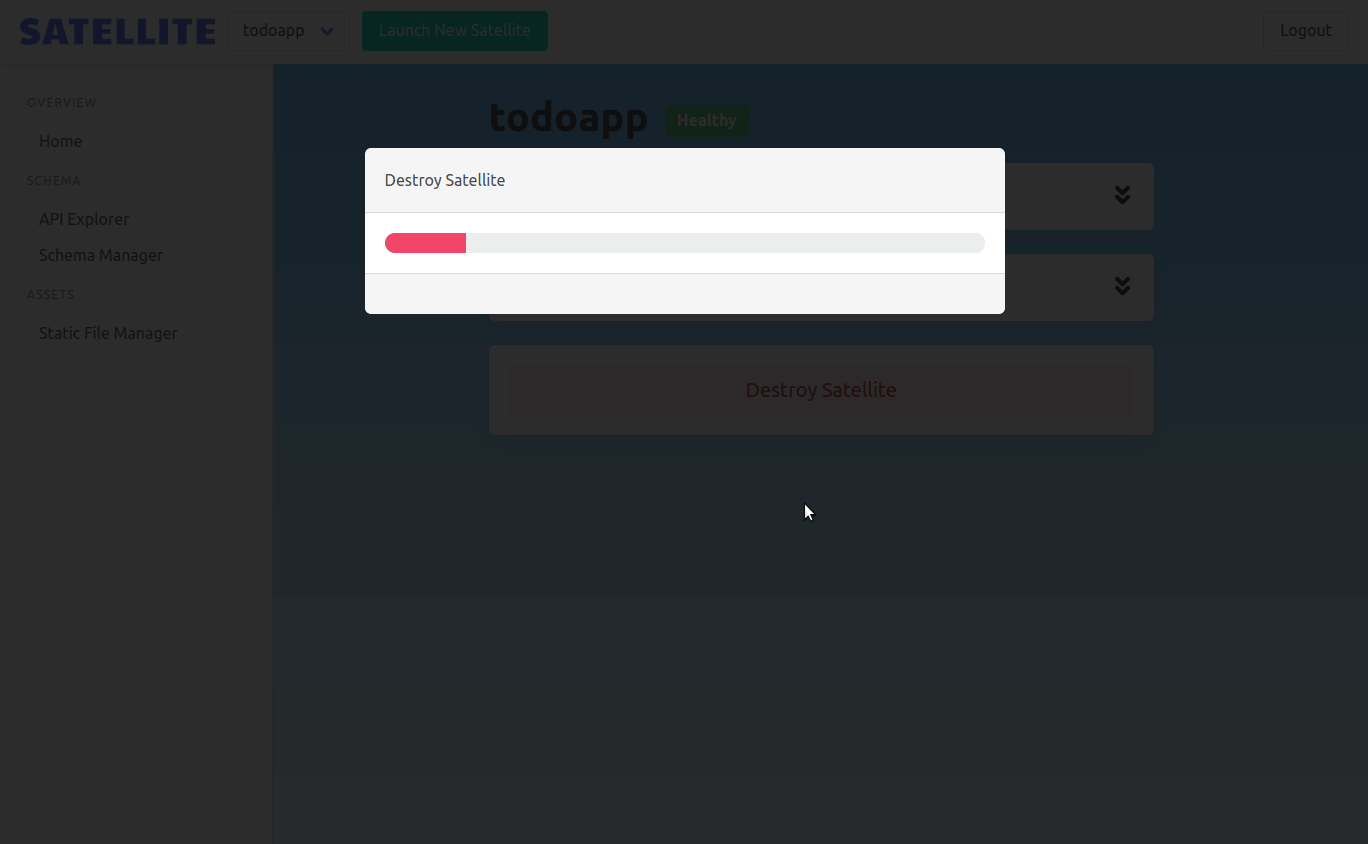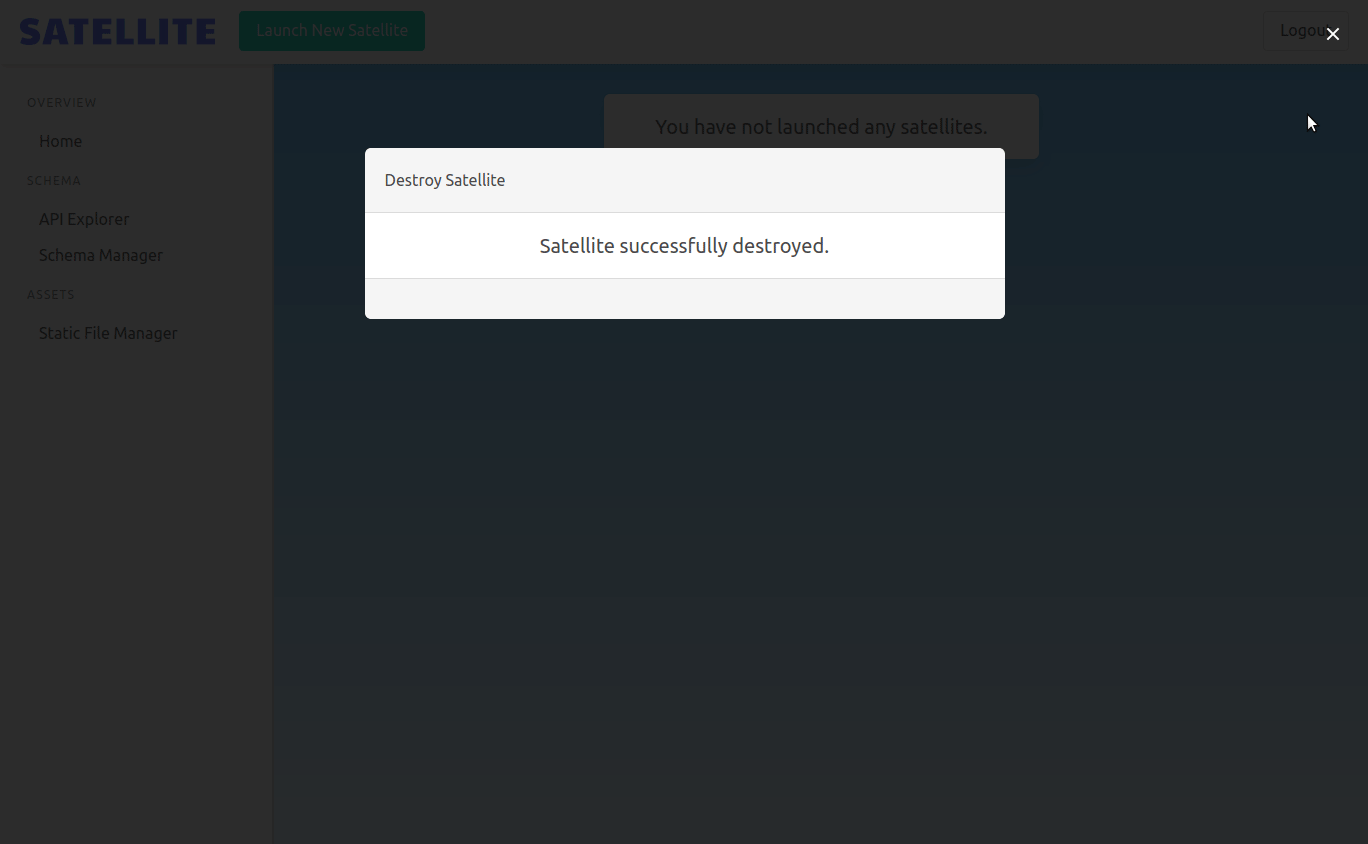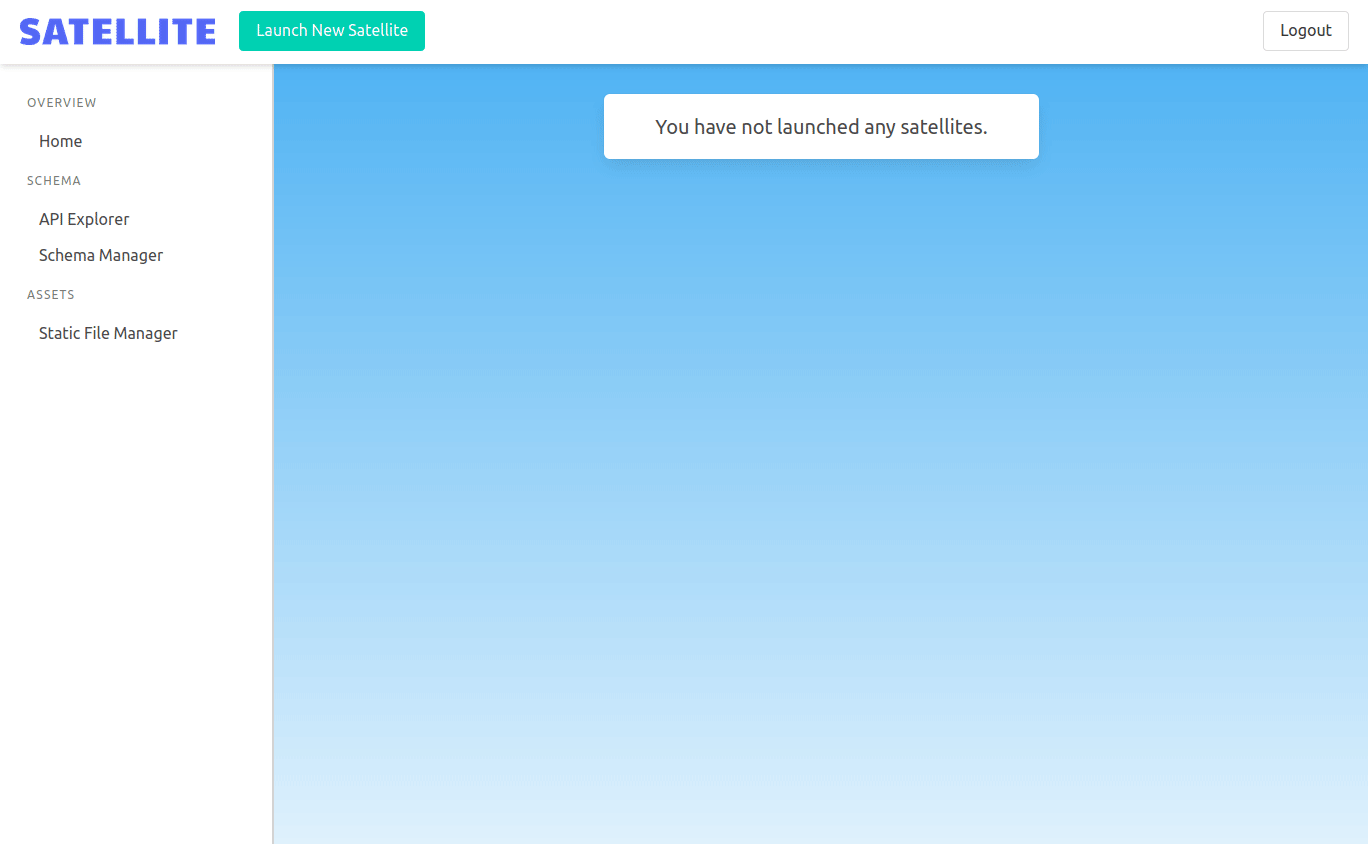
An Nginx container running in the cluster serves the admin panel as static files. A containerized Express app handles requests to manage backends. Lastly, a container running Postgres manages user accounts and the backends they've created.
Now we had a GUI for Satellite backends to be spun up and torn down. Next, we needed an easy way for developers to manage the GraphQL schema of each backend.
One of the benefits of using Dgraph is the ability to easily update its GraphQL schema. We built a schema viewer into the admin panel to see Dgraph's schema. It uses Codemirror to provide GraphQL syntax highlighting.
Uploading new schema is done by uploading a schema file in the admin panel. It's sent in a POST request to the admin backend. The admin backend extracts the backend ID and uses it to proxy the request to the correct Satellite backend.
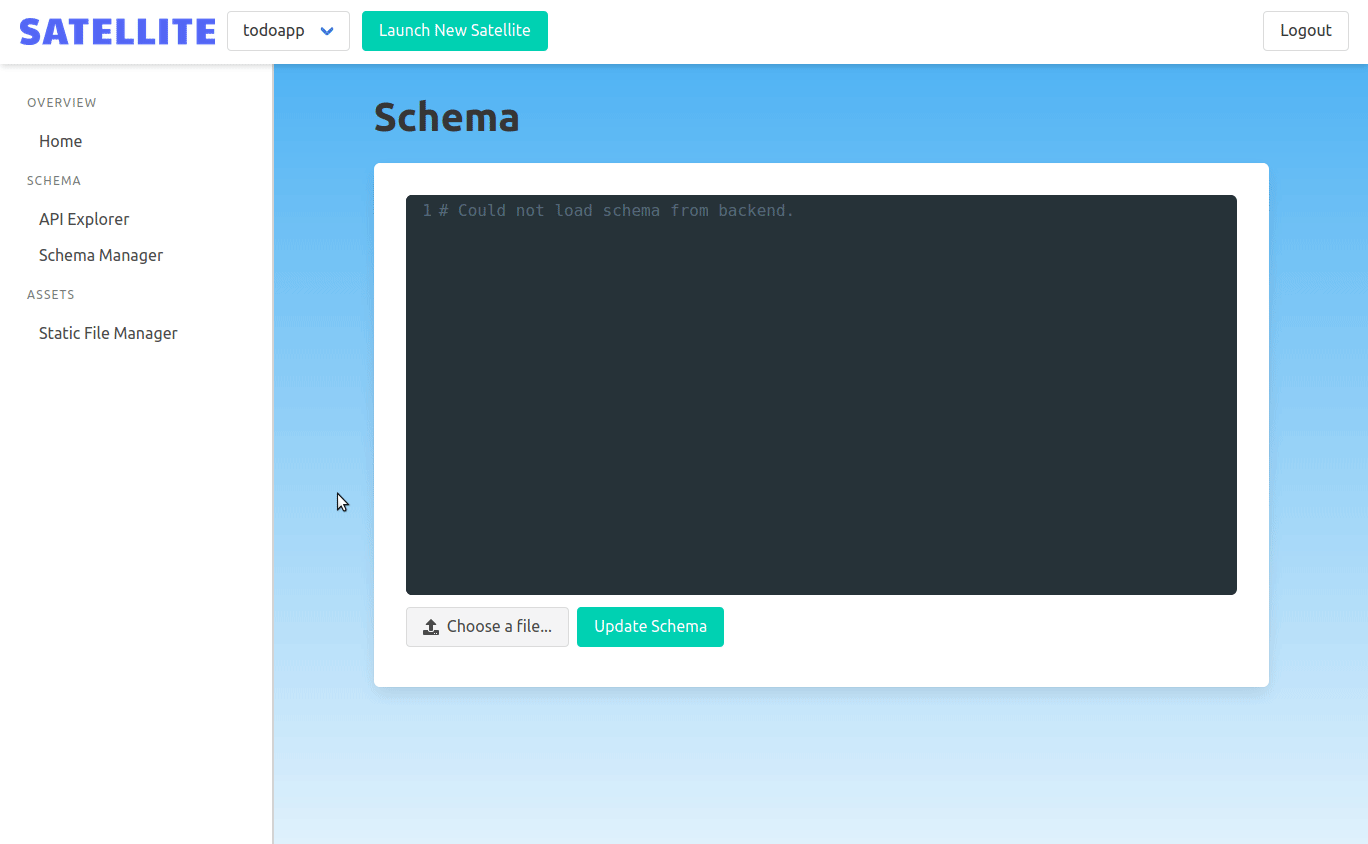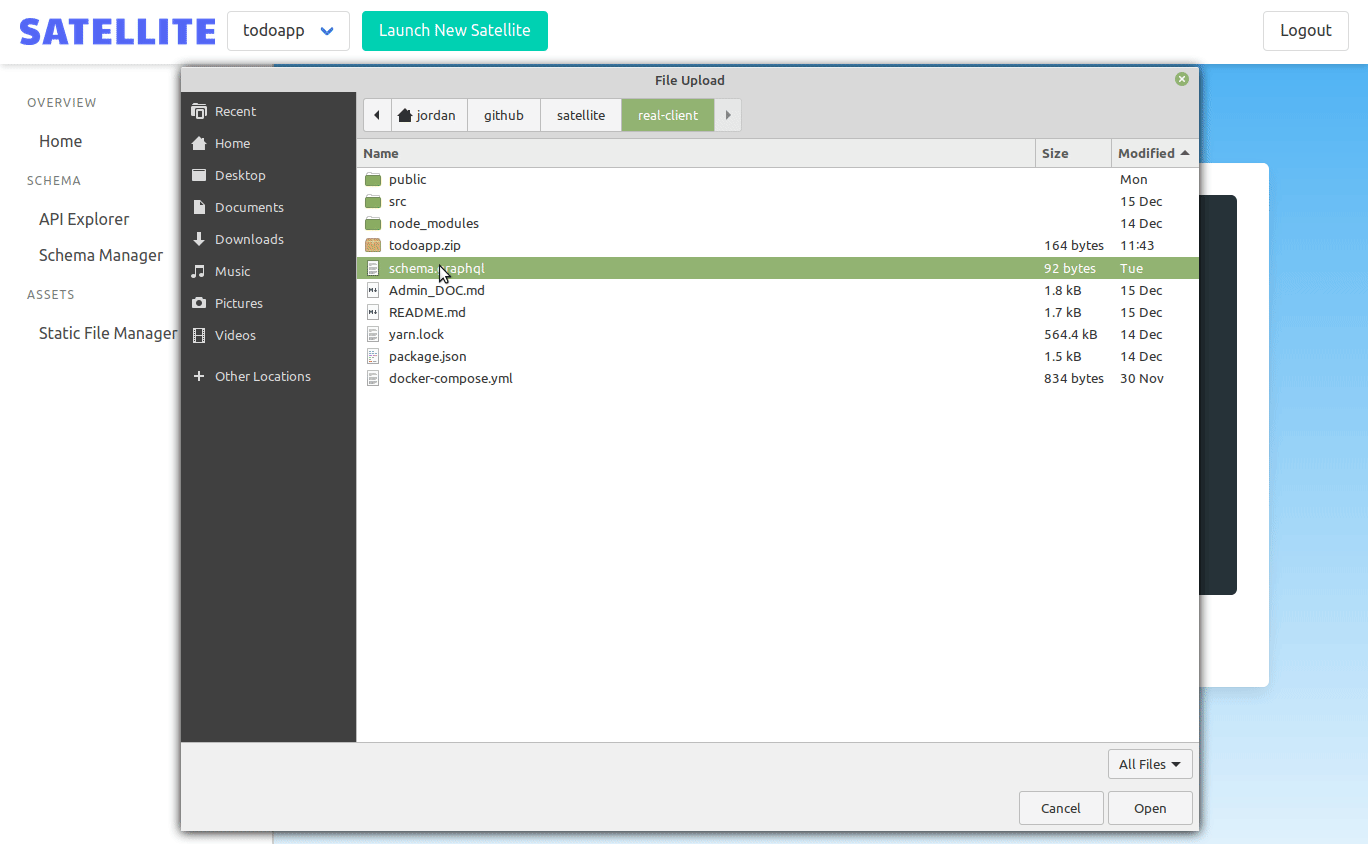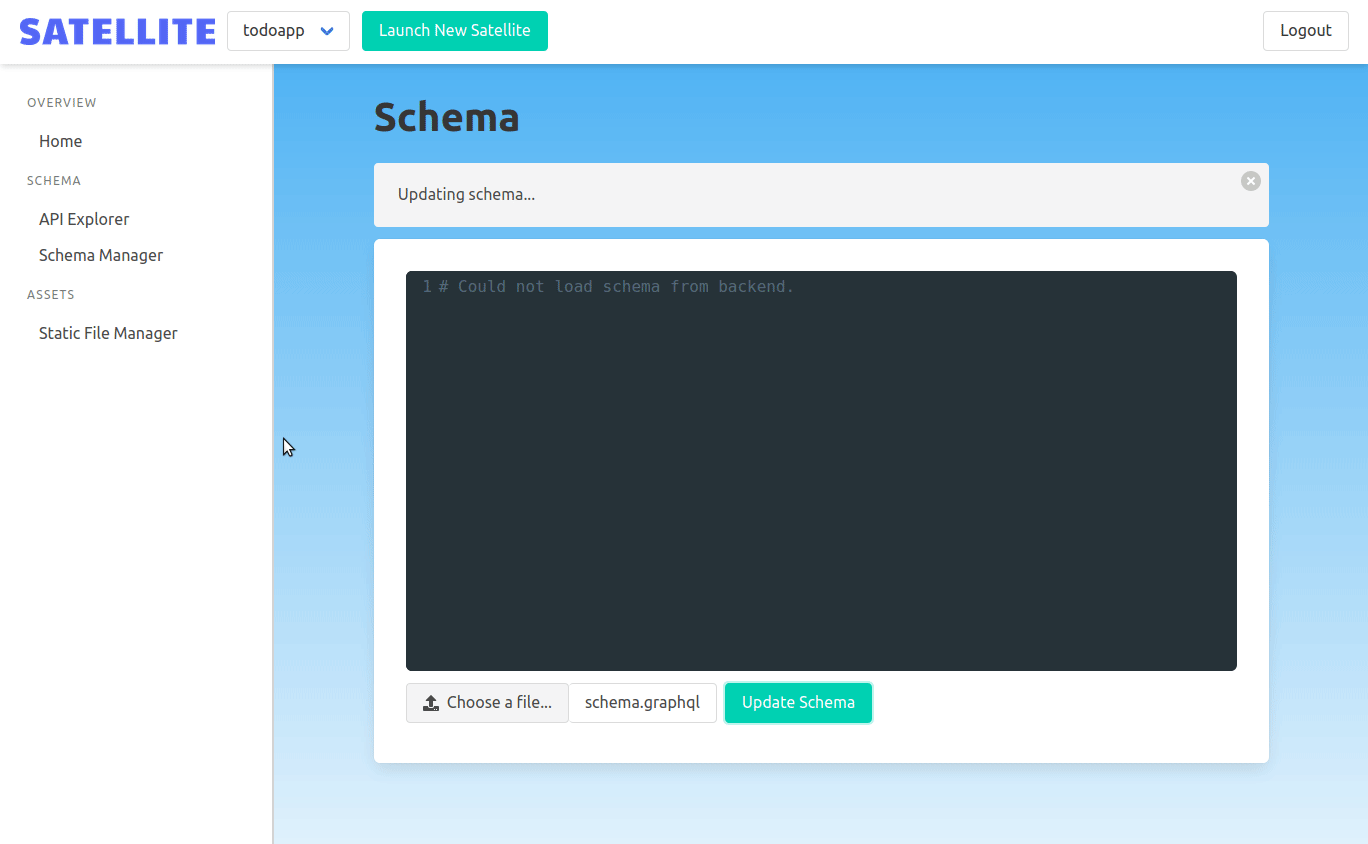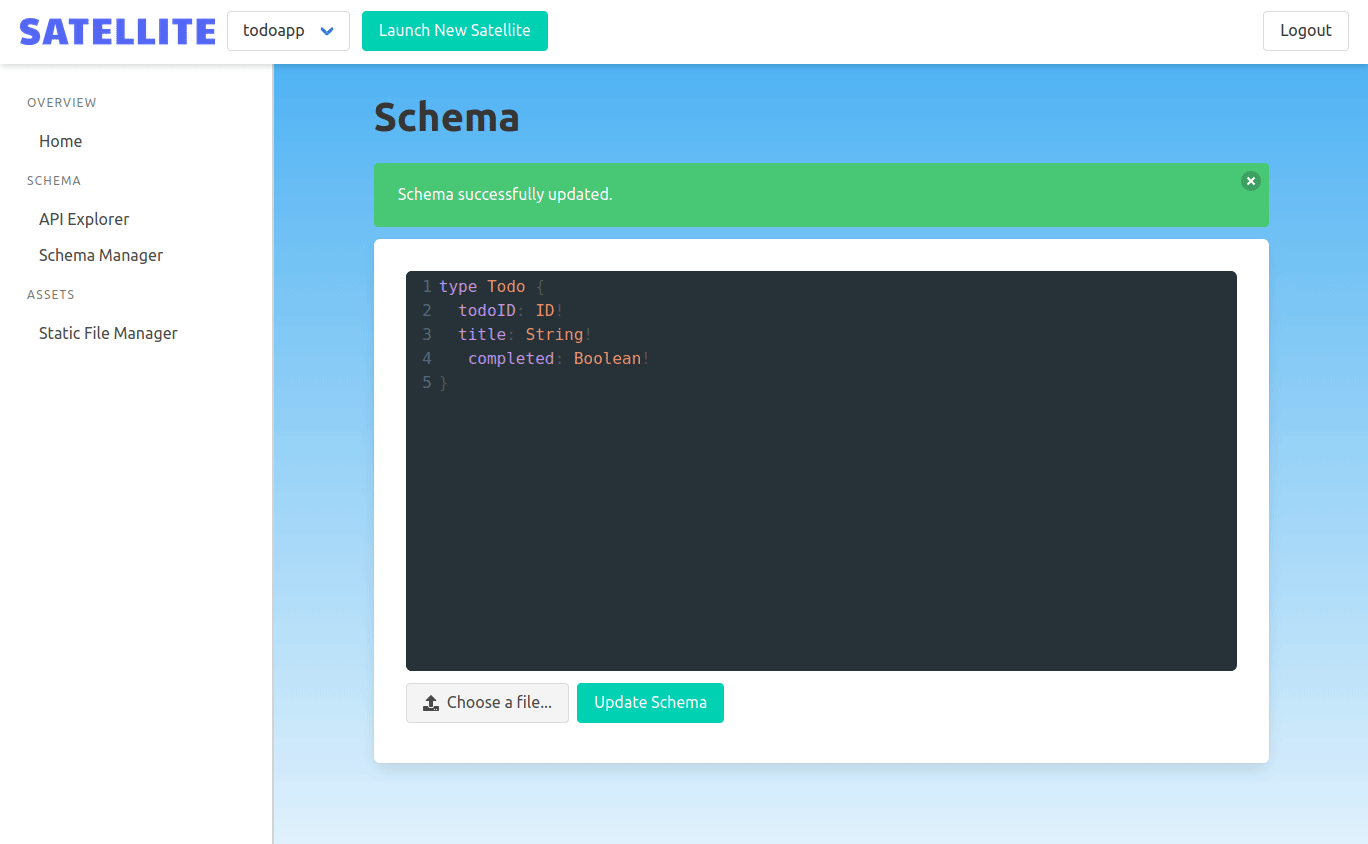
Uploading the GraphQL schema is one thing, but we also wanted it to be easy to explore the resulting GraphQL API. We wanted the rich client-side experience that is part of what makes GraphQL so popular.
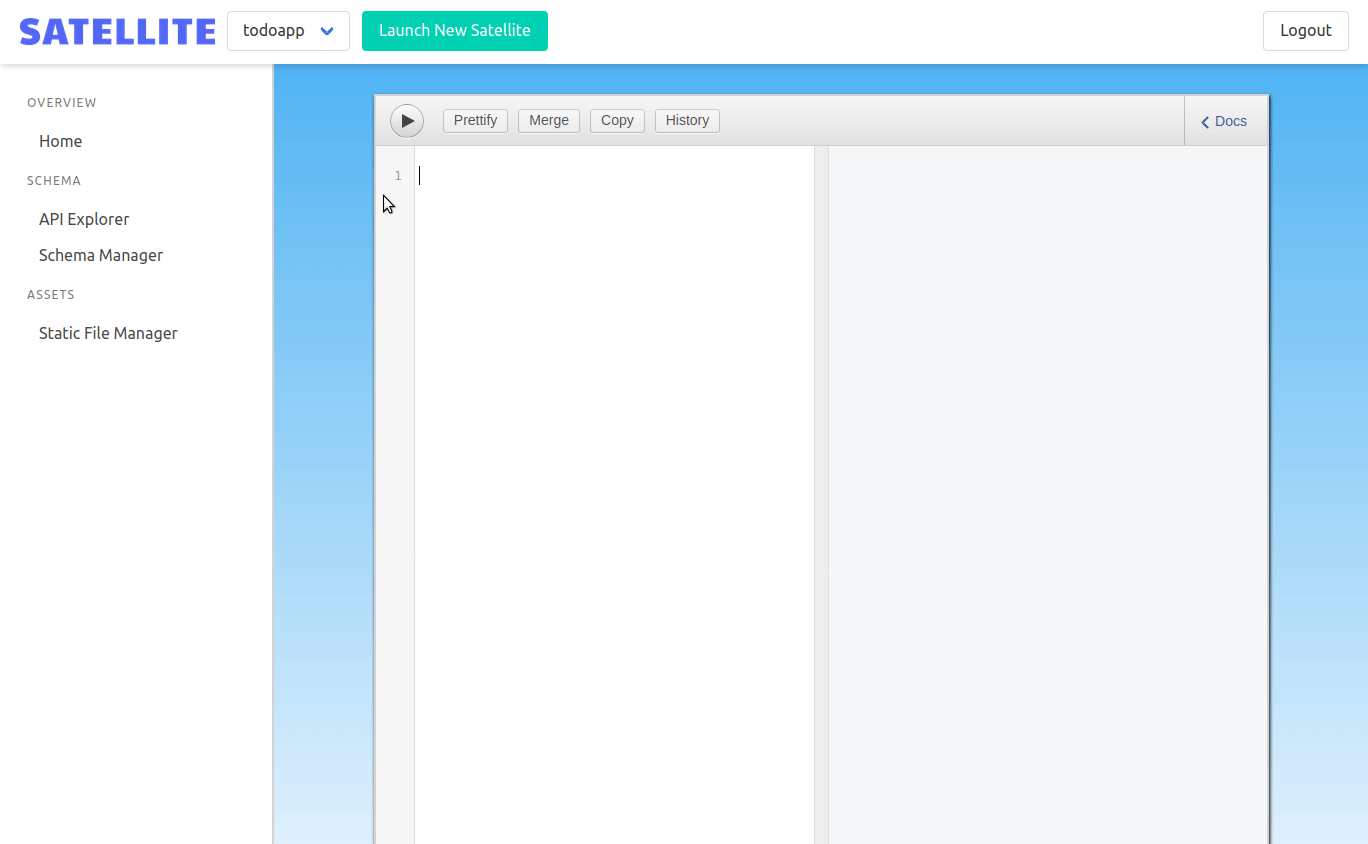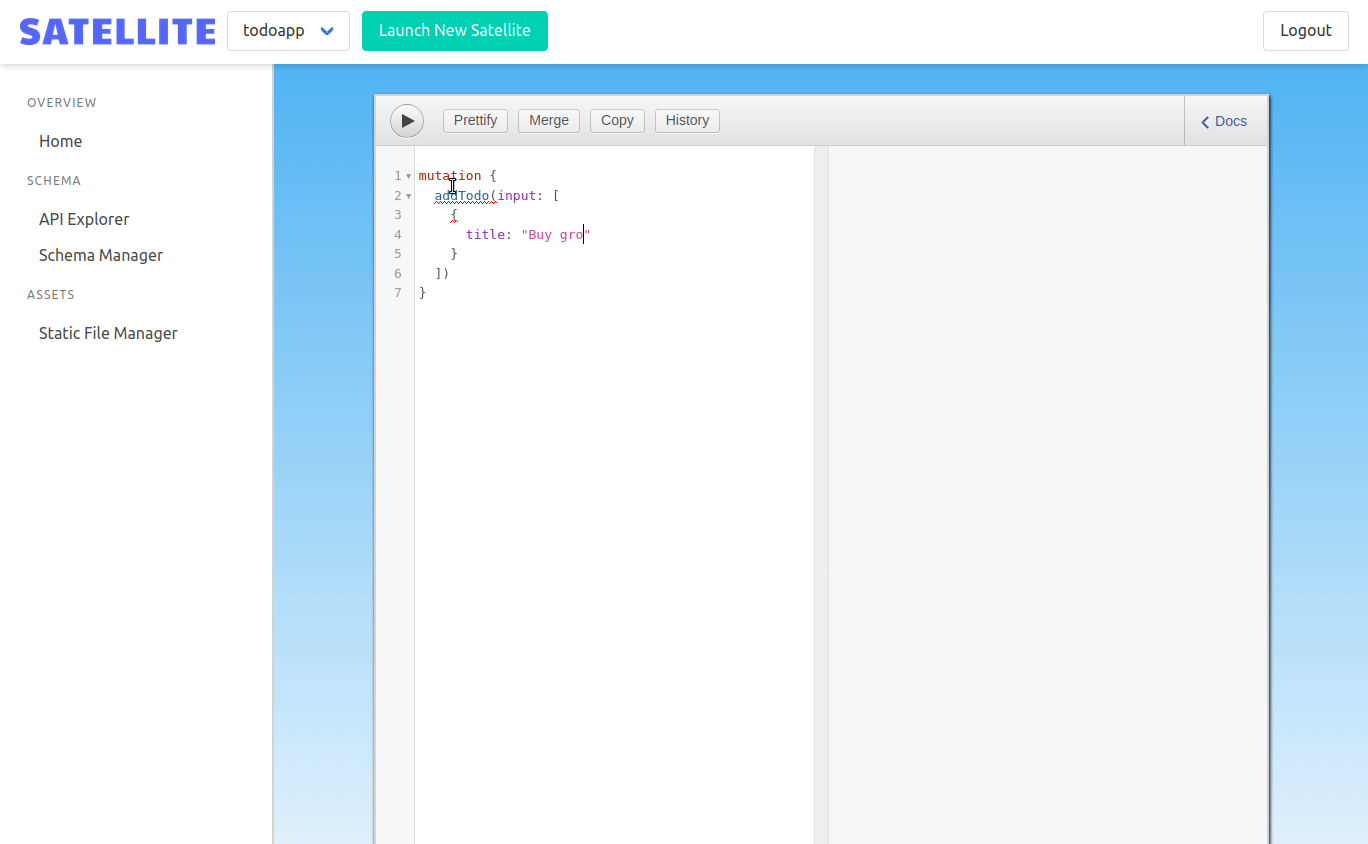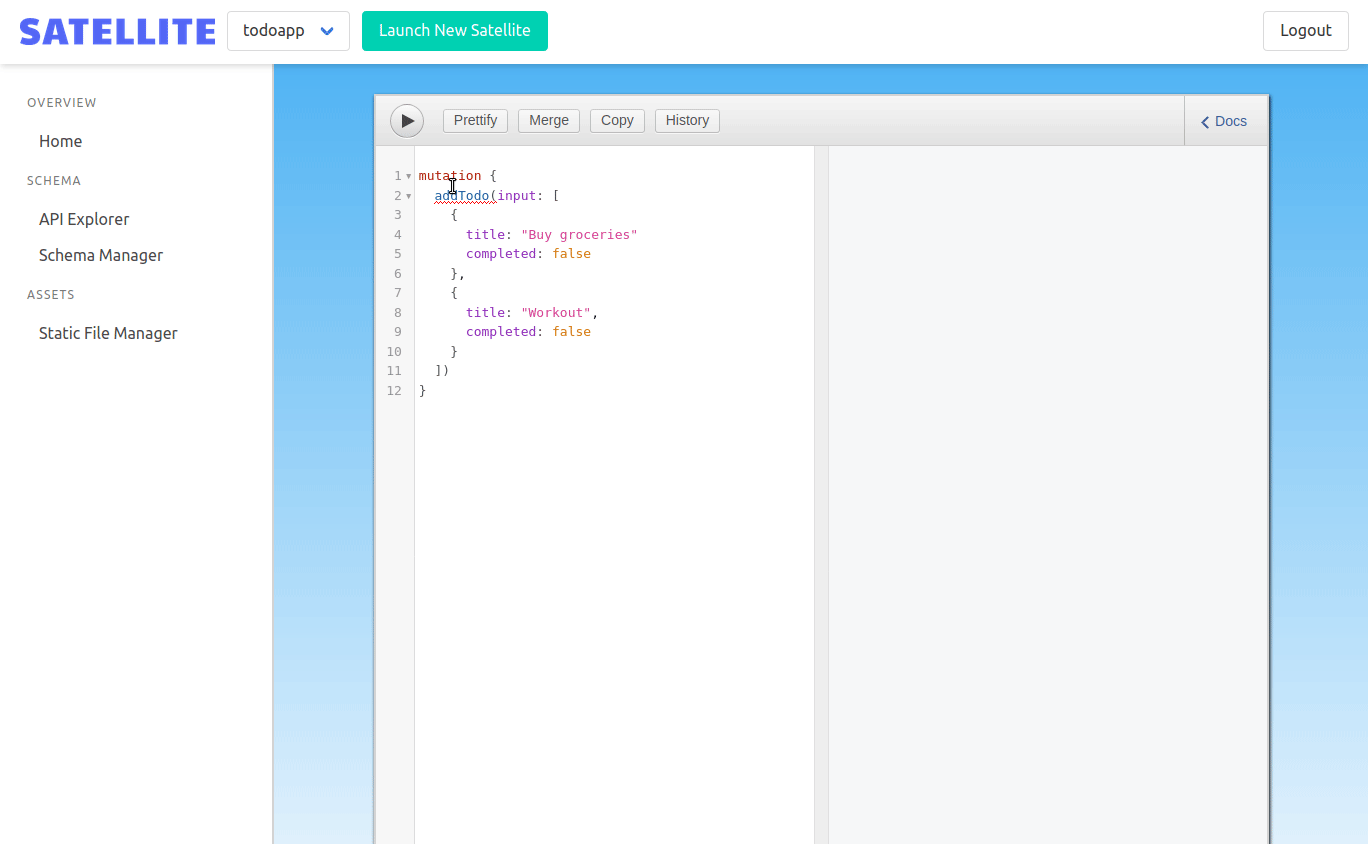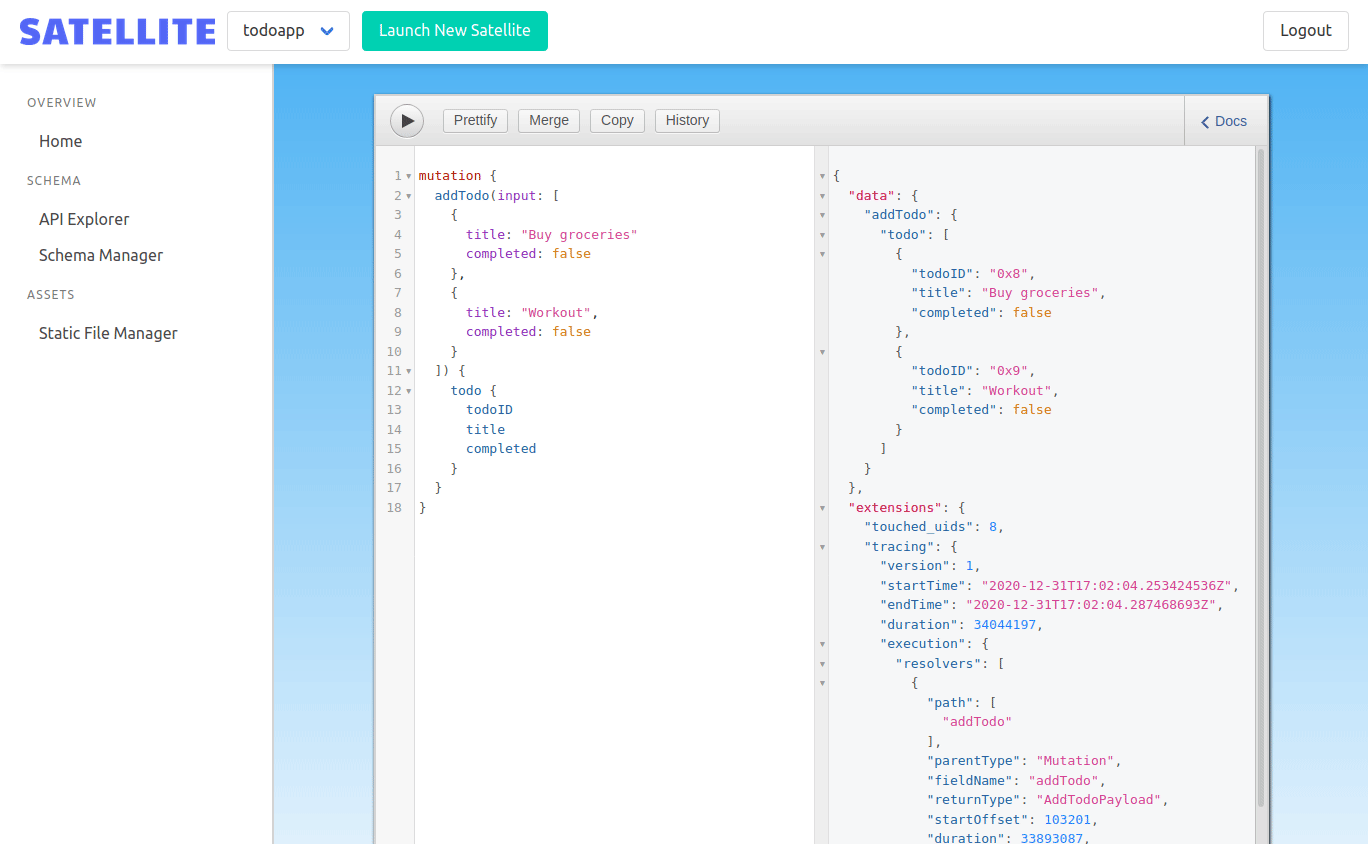
GraphQL gives developers the ability to introspect their schema and even make queries and mutations against it. We wanted to let frontend developers do this within the admin panel. They should be able to test their schema, make queries against it, and even populate the Dgraph instance with data to power their application.
To do this, we used GraphiQL. GraphiQL is an IDE for GraphQL and makes it easy for frontend developers to test and explore their GraphQL schema. To make this work, we needed to make a query to the /graphql endpoint of the currently selected Satellite. This endpoint allows us to make an introspection query to populate the GraphiQL IDE. Our admin panel makes a POST request with the current backend ID to the admin backend, which proxies the request to the correct backend.
We wanted to give frontend developers a convenient way to host their frontend static files. The owner of the backend can upload a single .zip file containing all the static assets that they want to be served by their application.
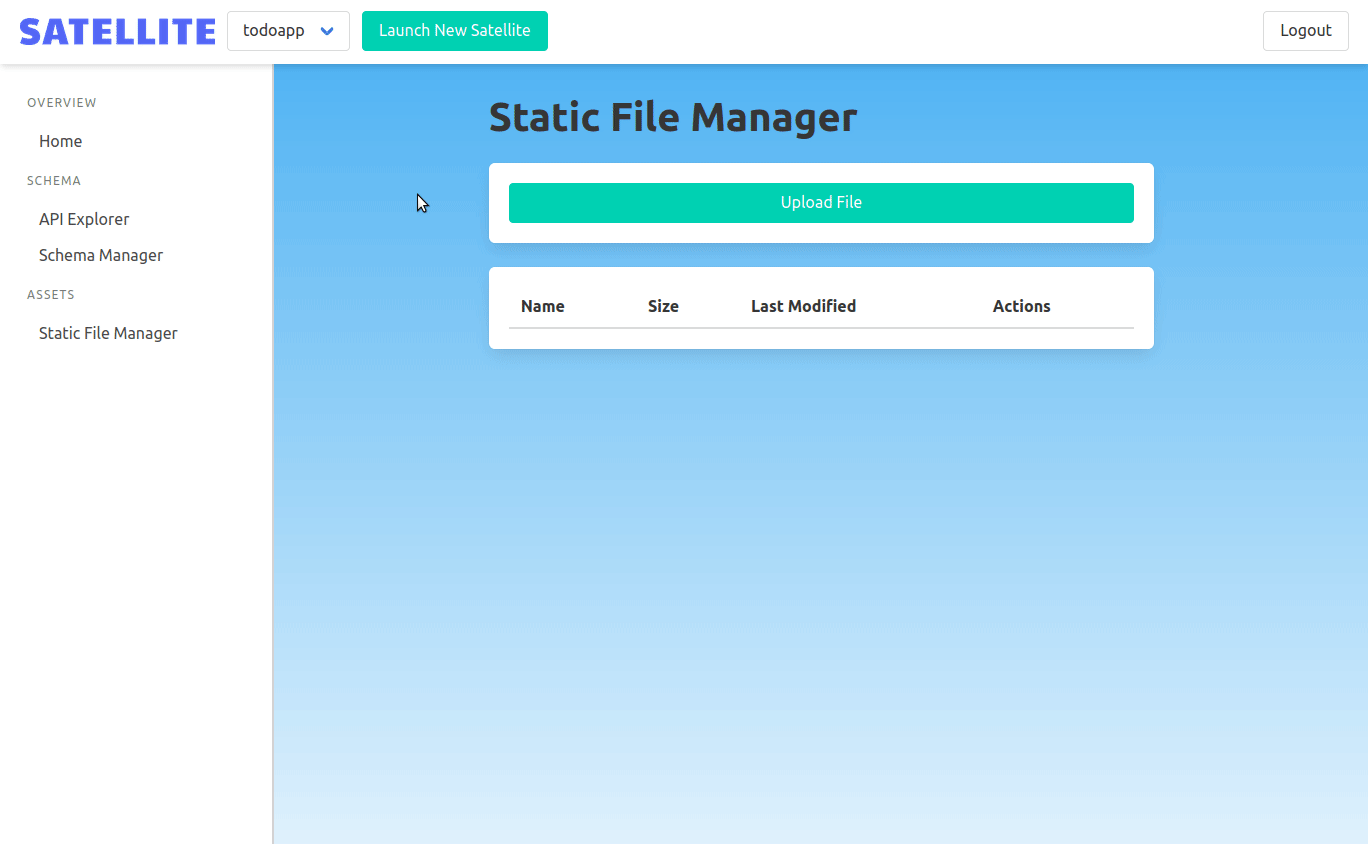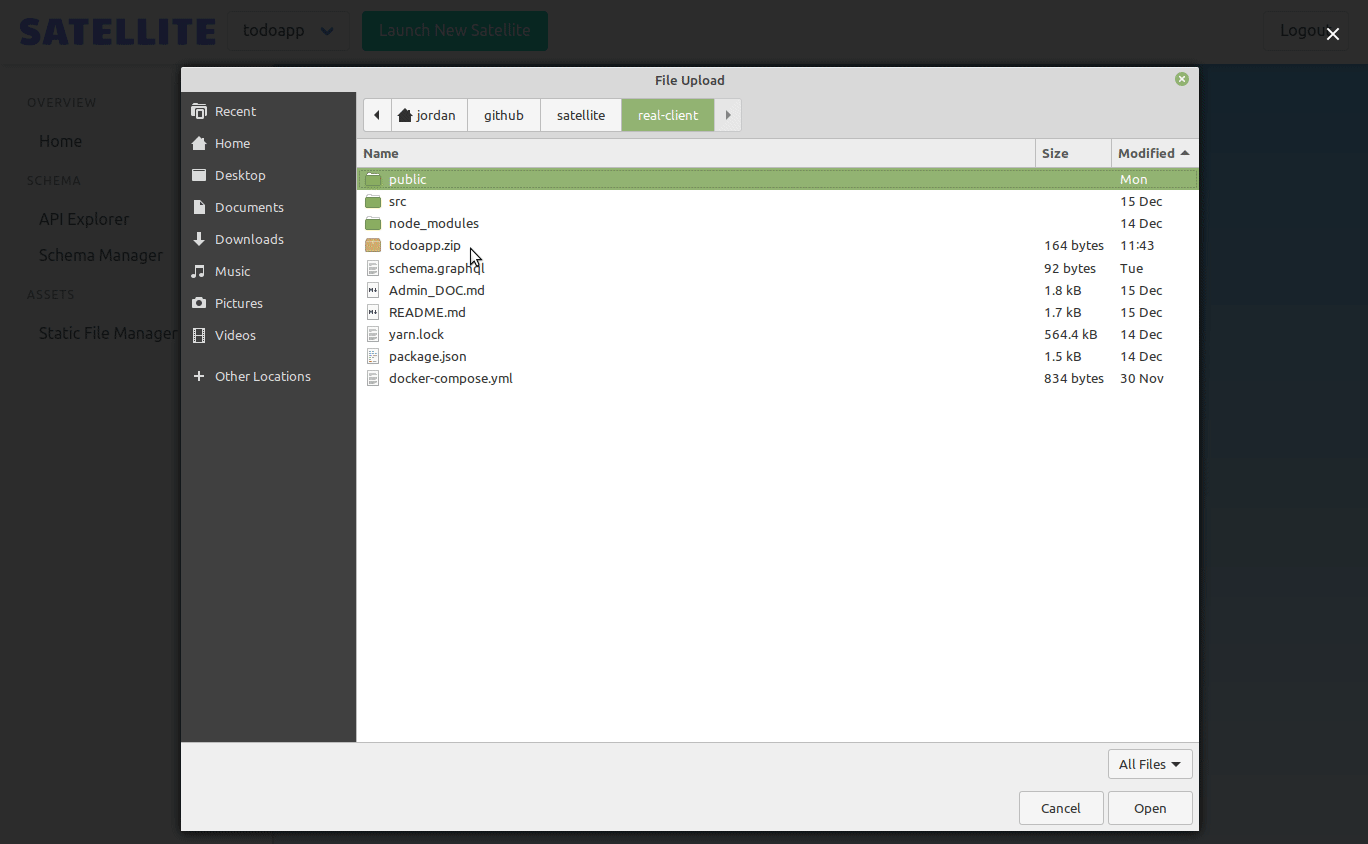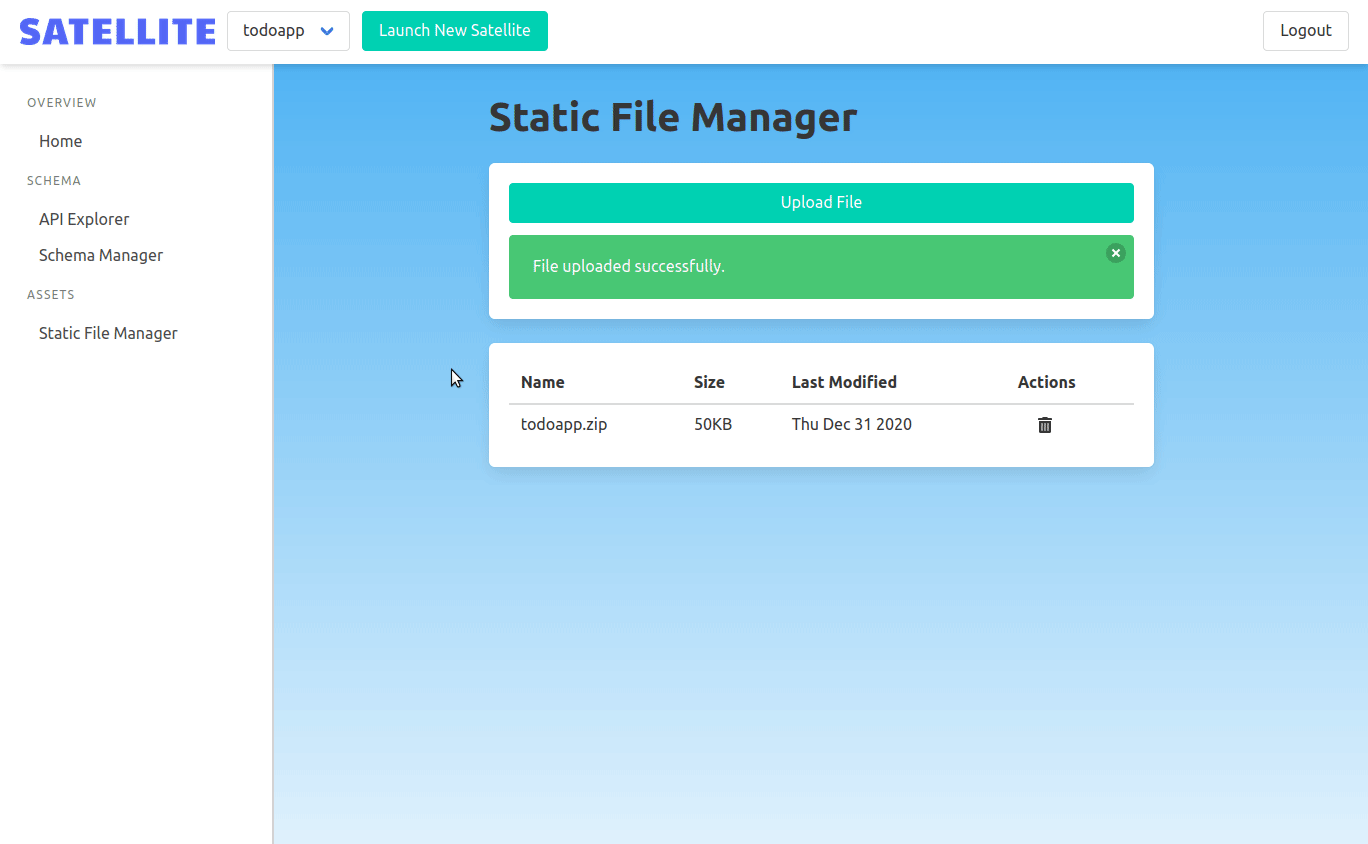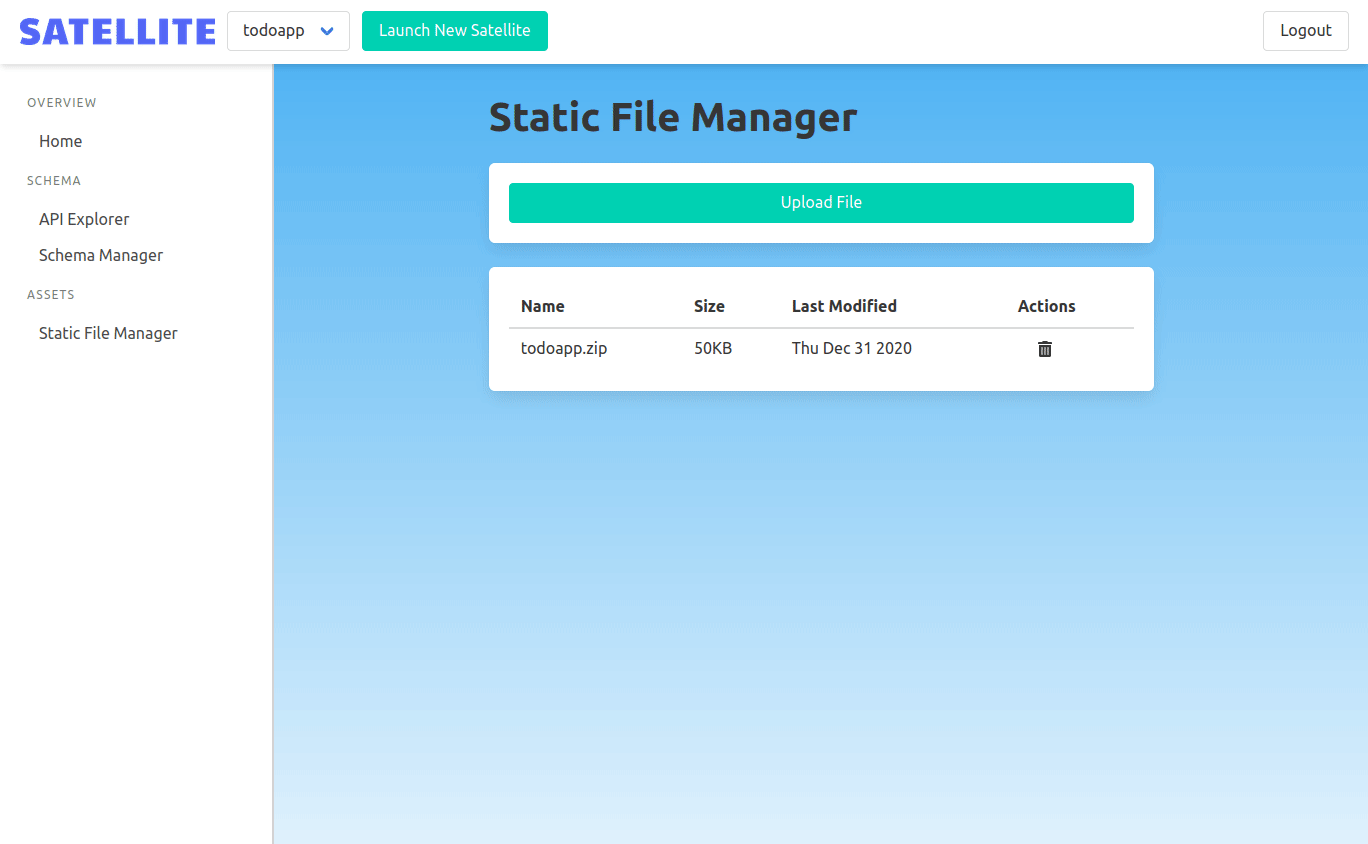
When a frontend developer uploads a file, the admin backend then uses Kubernetes API to copy the files into the correct instance's Nginx pod.
With the admin panel complete, we had a simple, intuitive interface. This brought us to the conclusion of Satellite's design. We had created a GraphQL Backend-as-a-Service, easy to use and deploy, that could support any number of GraphQL backends!
We are looking for opportunities. If you liked what you saw and want to talk, please reach out!

Cleveland, OH

Ontario, CA

Croton on Hudson, NY

Scappoose, OR